Generativ AI laver billeder: Hvordan virker Dall-E 2 og Midjourney?


•
14 min læsetid

Generativ kunstig intelligens er en type af kunstig intelligens (AI), der kan skabe nye, originale artefakter ved at bruge algoritmer til at generere indhold som f.eks. tekster, billeder, videoer, tale og musik, ud fra et prompt-input. De mest kendte generative AI-applikationer er ChatGPT, Bing Chat, Google Bard (tekst-genererende) og Dall-E 2, Stable Diffusion og Midjourney (billed-genererende).
I denne artikel vil vi kort forklare, hvordan kunstig intelligens kan generere billeder ud fra en beskrivende tekst. Vi sammenligner også 5 af de mest benyttede systemer, plus Microsoft Bing som i seneste udgave også kan generere billeder.
I en række kommende artikler, dykker vi ned i forskellige måder at anvende de billedgenererende kunstige intelligenser
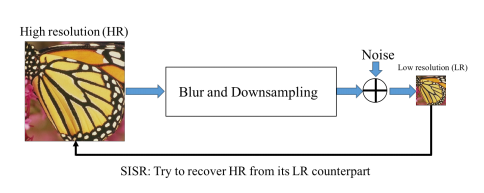
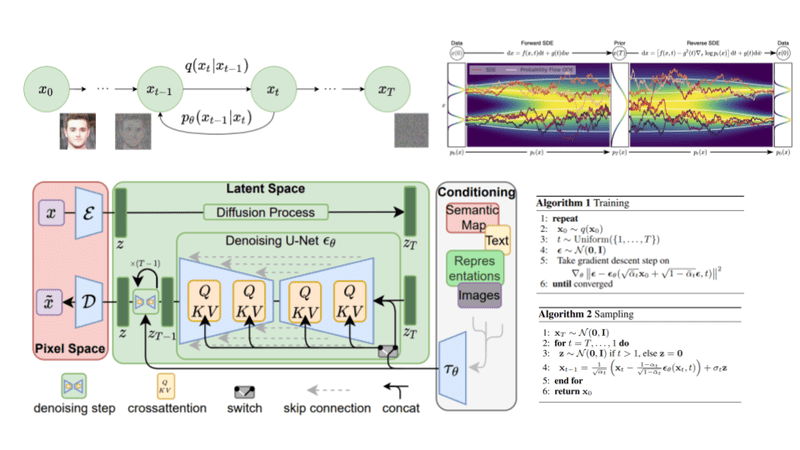
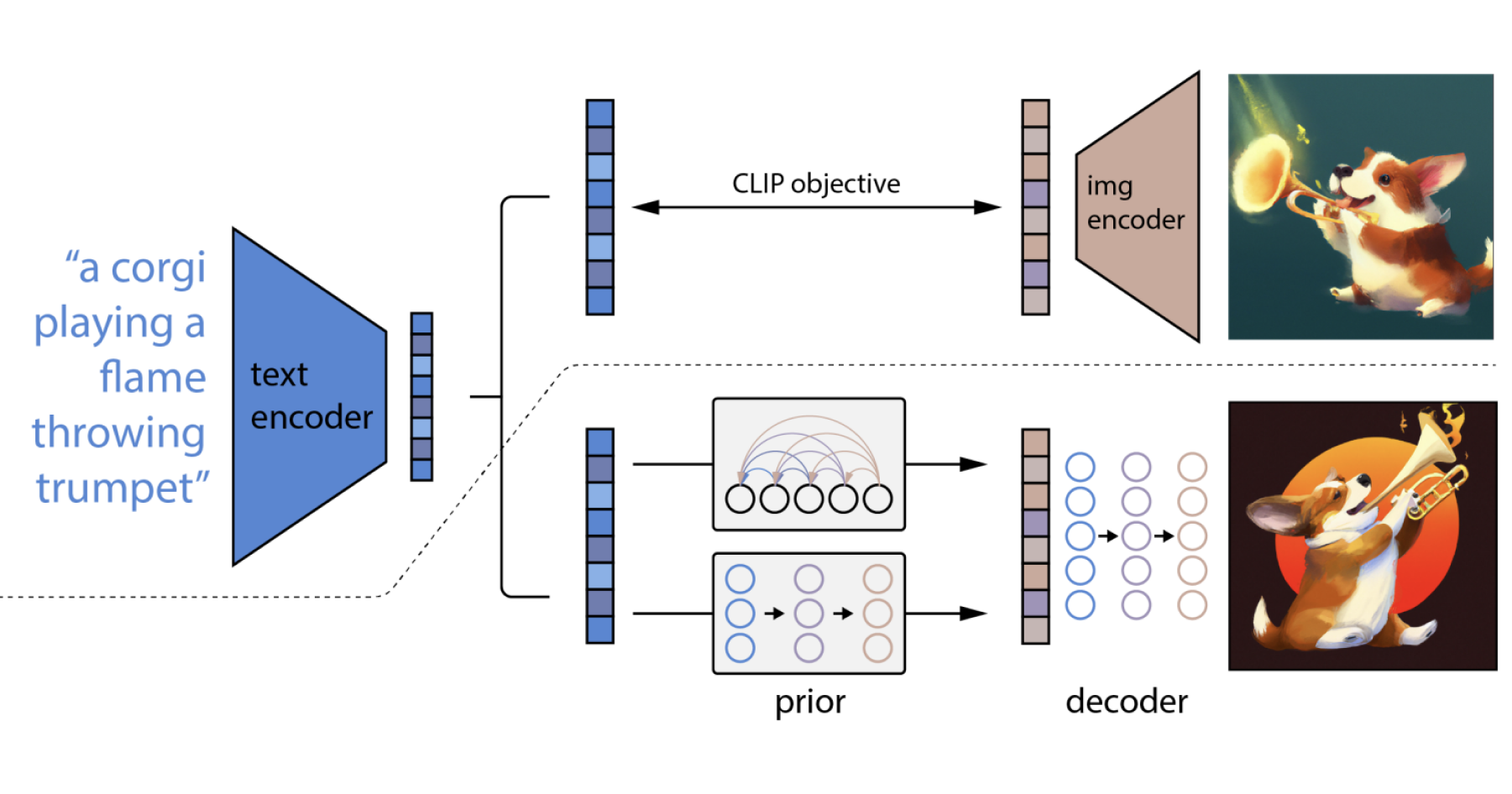
De billedgenererende kunstige intelligenser er baseret på en teknologi der kaldes diffusion. Kort fortalt virker de ved at ødelægge og genopbygge billeder igennem en række trin, og lære af processen.
Første trin i processen (forward) er, at gradvist at ødelægge et billede ved at tilføre større og større mængder af gaussisk støj, indtil billedet er helt væk.

Herefter køres processen baglæns (reverse), og støjen formindskes gradvist igennem en masse trin, for at skabe et billede igen. Dette sker i et neuralt netværk der får input fra billedet med støj og en tekst der beskriver billedet, og output er i hvert trin et billede med mindre støj. Modellen lærer hele tiden af de enkelte trin, og ender ud med at genskabe billedet igen. Modellen lærer altså at generalisere tekst til billeder ved at konvertere det støjende billede tilbage til dets oprindelige repræsentation. På denne måde lærer modellen, hvordan man matcher en tekstprompt til et billede. Når modellen er trænet på flere millioner billeder med tilhørende beskrivelser, er den i stand til at generere billeder ved at starte med tilfældig støj, en tekstprompt som beskriver det man ønsker et billede af, og ender med et billede af det man ønsker.
Til sidst opskaleres billedet til den ønskede størrelse vha. en algoritme. Denne algoritme virker lidt på samme måde som diffusionsprocessen (forward-reverse) ved at kunne forudsige et billede i høj opløsning, der vil kunne nedskaleres til at ligne det originale billede med lav opløsning. Efter træning på en masse billeder, kan den lave højopløselige billeder ud fra billeder med lav opløsning.
Hvis du vil vide mere om processen bag billedgenerering og matematikken bag, kan du læse om det i linksamlingen nederst på siden. Teorien er meget kompleks og involverer avanceret matematik, som bl.a. inkluderer Markov-kæder.
Hvad kan disse billedgenererende kunstige intelligenser så, og hvad er forskellene på dem? Vi har kigget nærmere på de mest benyttede systemer, nemlig Midjourney, Dall-E 2, Stable diffusion, Adobe Firefly og BlueWillow.
| Pris | Copyright | Redigering | Sværhedsgrad | Kvalitet | |
|---|---|---|---|---|---|
| Dall-E 2 | Betalt | Nej | Ja | Nem | Mellem |
| Midjourney | Betalt | Nej | Nej | Svær | Høj |
| Stable Diffusion | Betalt/gratis | Nej | Nej | Svær | Lav |
| Adobe Firefly | Gratis | Ja | Ja | Nem | Høj |
| BlueWillow | Gratis | Nej | Nej | Svær | Høj |
| Microsoft Bing | Gratis | Nej | Nej | Nem | Mellem |
Den mest simple at gå til er OpenAI's Dall-E 2. Har man allerede lavet en ChatGPT-konto hos OpenAI, kan man logge ind med den, og ellers skal man starte med at lave en konto.
Når det er gjort, kan man tilgå Dall-E 2 her: https://labs.openai.com/ og begynde at udforske tekst-til-billede. Man får 15 credits gratis hver måned (en credit er en forespørgsel til Dall-E 2), og herefter skal man betale for flere credits ($0.020 pr. billede i 1024x1024 som er max. opløsning)
Dall-E 2 er trænet på en blanding af offentligt tilgængelige billeder og billeder som OpenAI har købt licens til. Modellen har en række begrænsninger, som sikrer at den ikke kan lave billeder der overtræder OpenAI's retningslinjer, f.eks. vold, seksuelle, ulovlige eller politiske billeder. Disse kan ses her. Du risikerer at blive udelukket fra at bruge Dall-E 2 hvis du forsøger at overtræde dem. Ifgl. OpenAI ejer du de billeder du skaber og må gerne bruge dem kommercielt.



Dall-E 2 billeder - af Michael Howe-Ely
Midjourney er lidt mere kompliceret at komme i gang med, da den kører som en Discord-bot. Har man først styr på Discord og har fået installeret Midjourney, er det meget nemt at bruge. Der findes en masse vejledninger til installation på nettet.


https://support.discord.com/hc/en-us/articles/360045138571-Beginner-s-Guide-to-Discord
Midjourney er en lille selvstændig forskningsvirksomhed fra San Fransisco, som arbejder med en kunstig intelligens der kan skabe billeder fra en tekst. Man kan prøve Midjourney gratis (i øjeblikket er gratis prøve sat på pause), og skal derefter købe en af deres tre pakker til hhv. 10$, 30$ eller 60$. Jo dyrere plan, jo hurtigere genereres billederne, og jo flere samtidige kørsler kan man sætte op. Man køber en mængde GPU-tid pr. måned og ikke et antal billeder.
Midjourney er trænet på billeder hentet fra Internettet - ukritisk og uden at sikre rettigheder fra ejerne af billederne.. På samme måde som Dall-E 2, er Midjourney begrænset ud fra nogle retningslinjer der udelukker skabelse af billeder der er disrespektfulde, ulovlige, aggressive eller seksuelle. Også Midjourney udelukker brugere der forsøger at skabe billeder der overtræder disse retningslinjer. Man må gerne bruge Midjourney-billeder kommercielt, hvis man har en betalt konto. Ifgl. Midjourney ejer man de billeder, man skaber.



Billeder lavet i MidJourney
Stable diffusion er lavet af virksomheden Stability AI, sammen med forskere fra Ludwig Maximilian University i München. Stable Diffusion er frigivet som Open Source, så man i teorien kan køre det på sin egen computer (kræver en nyere Nvidia GPU med mindst 4GB VRAM). Man kan også tilgå Stable Diffusion via Dream Studio, hvor man gratis får 25 credits (svarende til ca. 125 billeder). Man kan købe yderligere credits for 10$ pr. ca. 5000 billeder.
Stable Diffusion er også trænet på flere milliarder billeder hentet fra Internettet. Stability Ai mener at træningen på copyrightede billeder ligger under "fair use"-doktrinet. Som de andre modeller har Stable Diffusion også et sæt retningslinjer og begrænsninger, der ligner de andres. Det er dog muligt at omgå, hvis man installerer modellen på sin egen computer. Stability AI skriver, dog noget forsigtigt, at man ejer billederne og må bruge dem kommercielt.
 TheLastBen
TheLastBen

Stregtegning lavet om til foto i Stable diffusion (Bùi Xuân Phái)



Adobe har for ganske nyligt (21. marts 2023) lanceret deres generative billedværktøj, som de kalder Firefly. I første omgang kun i en beta-udgave, som man kan skrive sig op til at prøve. Viden.ai har fået adgang til Firefly, og kan derfor beskrive det her.
Adobe Firefly er et billedgenererings-værktøj som lige nu kører via et website, men som senere bliver implementeret i deres Creative Cloud programmer som Photoshop, Illustrator osv. Firefly kommer nemlig snart i en udgave, der kan lave vektorgrafik også. Fordelen ved Firefly er, at Adobe har trænet modellen på professionelle stock-billeder som de allerede har rettighederne til. Det skulle, udover at sikre rettigheder 100%, også give bedre billeder som output. Adobe arbejder også på, at grafiske designere kan få adgang til at træne modellen på deres eget arbejde, så den kan generere billeder i deres personlige stil.



Vi har BlueWillow med på listen over værktøjer hvor man kan lave billeder. Det virker på samme måde som MidJourney, men den helt store forskel er at det er gratis at bruge. I den gratis version kan du lave alle de billeder du vil, og du må efterfølgende bearbejde billederne og bruge dem kommercielt. Det er dog vigtigt at bemærke, at BlueWillow gerne må bruge din prompt og anvende billederne du har genrereret til egne formål.
Det skulle være muligt at købe sig til tjenesten, og så ejer du alle rettigheder til billeder du markerer som private eller laver i lukkede rum på Discord. Her vil du selv have alle rettigheder over billederne og de kan stadig bearbejdes og bruges kommecielt. Vi har ikke kunne finde nogle informationer om priser, men forventer at det er noget som kommer.
Ligesom MidJourney bruger BlueWillow Discord og man kan bruge de samme kommandoer. For at komme i gang med værktøjet anbefaler vi at læse deres egen dokumentation.


Det interssante ved BluwWillow er, at det samler mange andre værktøjer alt efter hvilken prompt man skriver, og derfor ved man ikke om det er Stable Diffusion eller en anden AI der generere billederne.
I vores tests er BlueWillow ikke på højde med de andre værktøjer, men det er et godt alternertiv til de betalte udgaver.





Billeder lavet af BlueWillow
Microsoft har torsdag d. 21/3-2023 offentliggjort, at Bing nu kan generere billeder ud fra en tekstprompt. Bing Image Creator, som de kalder deres værktøj, er allerede tilgængelig for alle der har preview-adgang til Bing Chat med indbygget kunstig intelligens.
Bing Image Creator benytter en avanceret version af OpenAI's Dall-E 2 billedgenererings-algoritme, og i deres preview-version der er tilgængelig nu, kan man kun prompte på engelsk. I preview-versionen har man adgang til 25 Boost-billeder (billeder der genereres hurtigt), og derefter sættes hastigheden ned.
Microsoft har med deres "responsive AI-principper" sikret, at man ikke kan lave bruge Image Creator til ulovlige eller skadeligt indhold. Se retningslinjerne her.
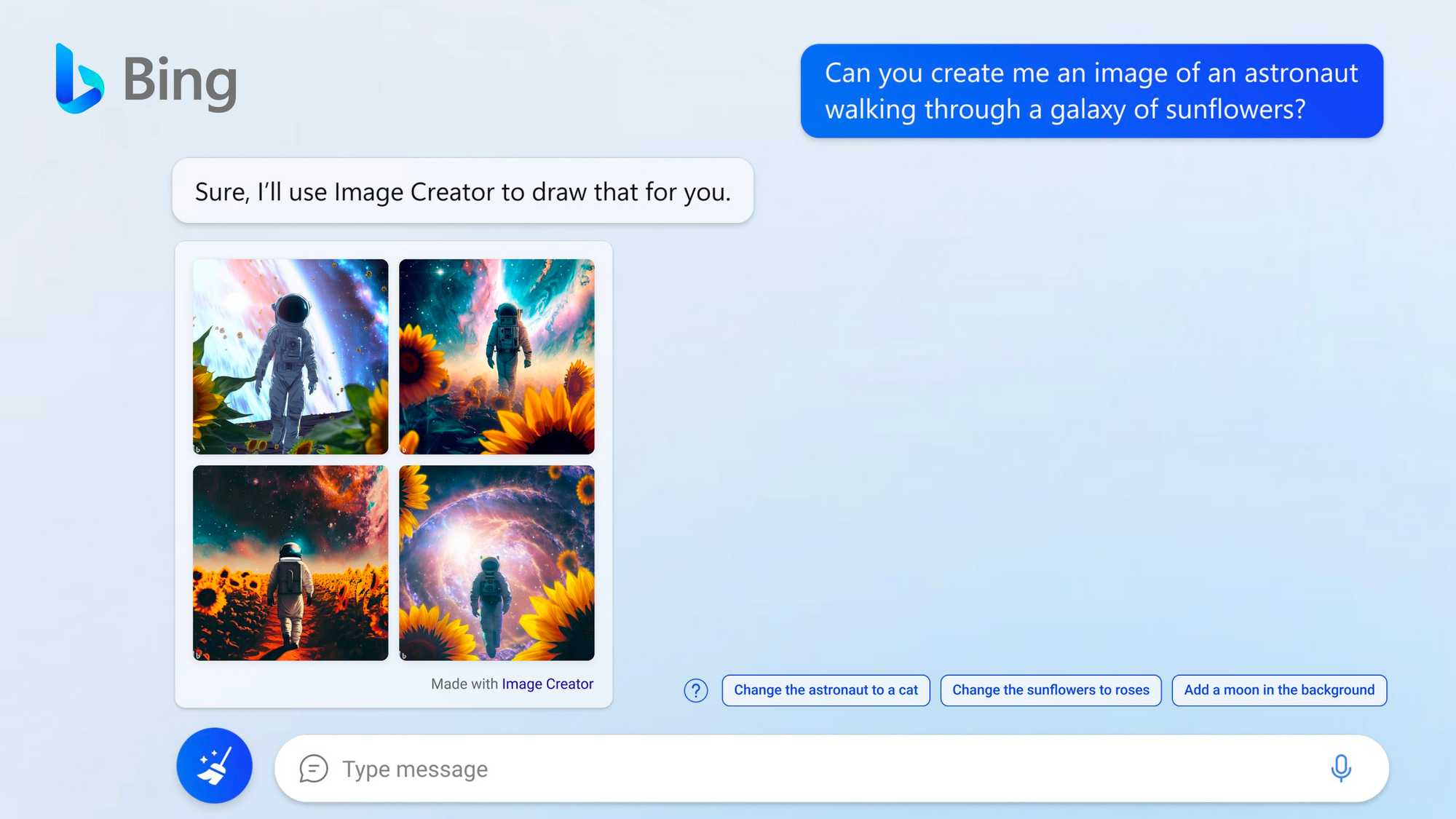
Man kan også generere billeder direkte i Bing Chatten, hvis man sætte samtalestilen i kreativ-mode:
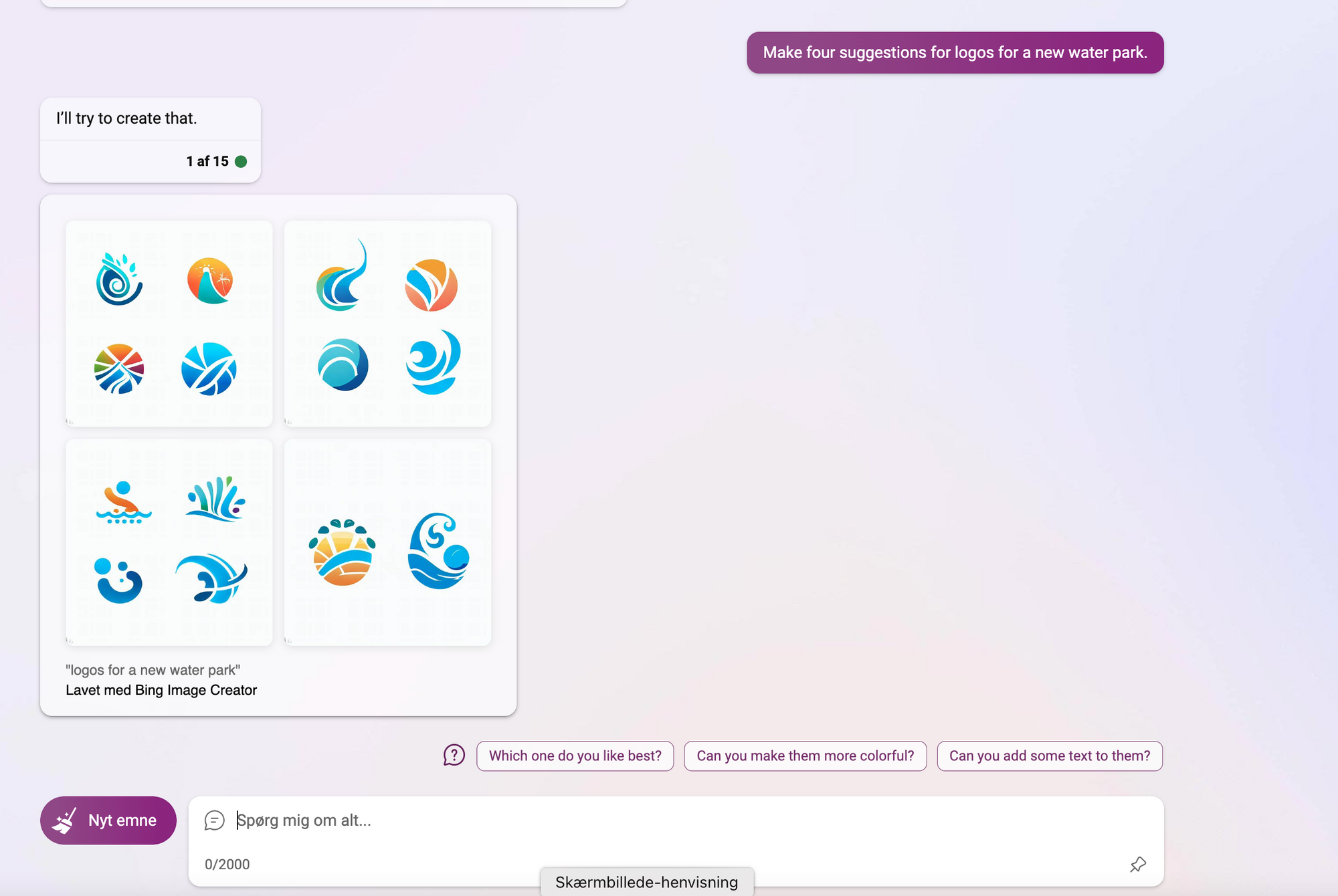
Man kan arbejde videre med billederne, men tekst går ikke så godt endnu. Den har samme udfordringer med tekst som alle andre generative billedgenererende AI's.
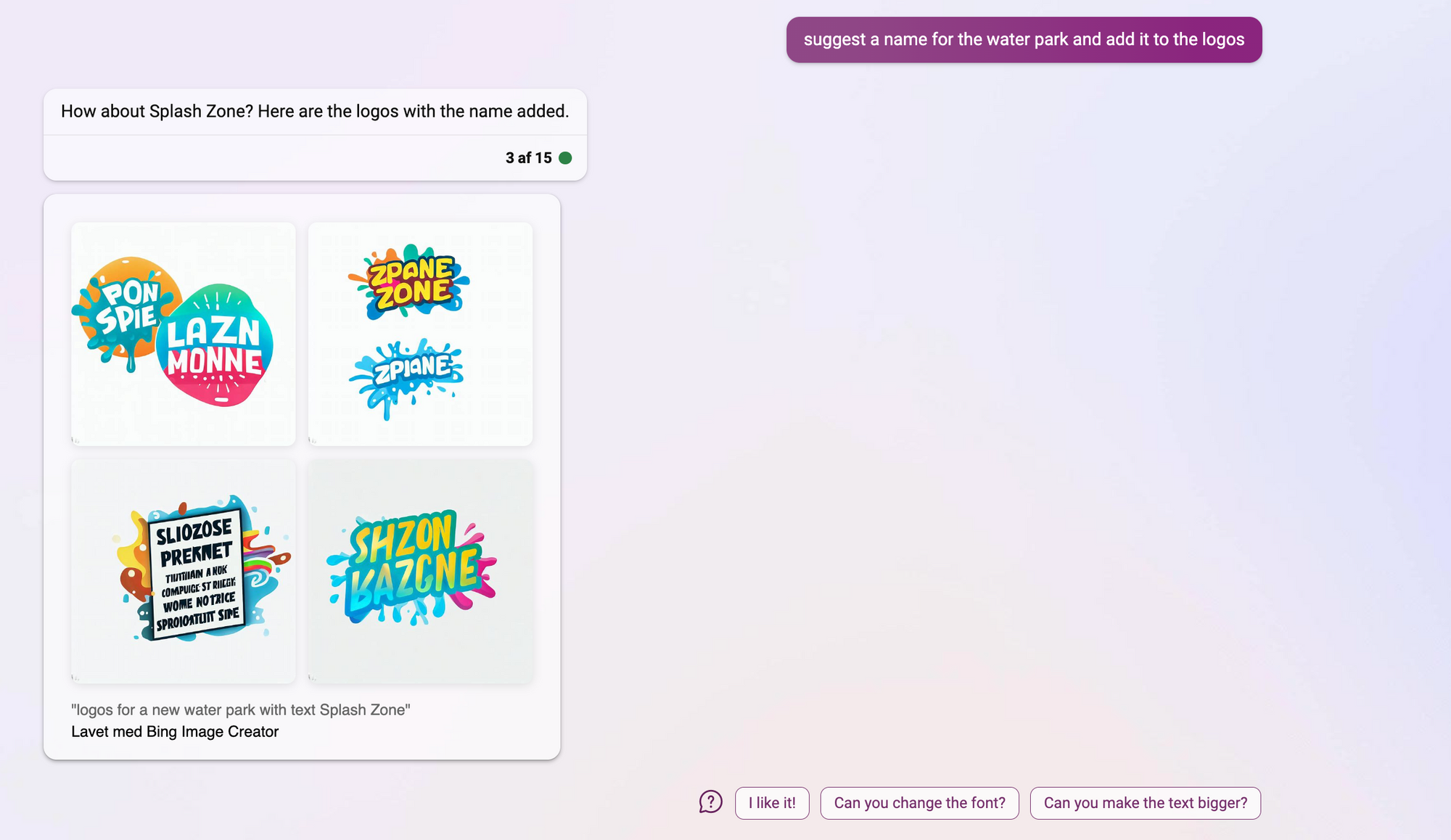



Billeder lavet af Bing Image Creator
 Frank X. Shaw
Frank X. Shaw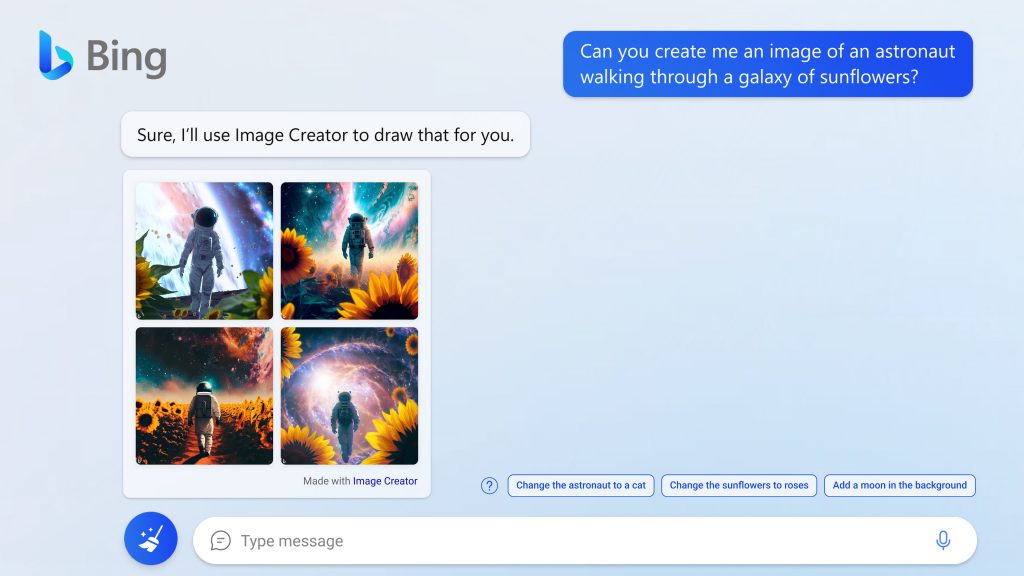
/cdn.vox-cdn.com/uploads/chorus_asset/file/24435316/STK150_Bing_AI_Chatbot_02.jpg)
 Frederic Lardinois
Frederic Lardinois
 af Visuel Storytelling
af Visuel Storytelling

 Ryan O’Connor
Ryan O’Connor
 Tom Hartsfield
Tom Hartsfield



.webp)


 Michael
Michael







