Når sprogmodeller genererer usandheder – ”hallucinerer” - del 2

•
14 min læsetid

Dette er anden del af artiklerne om hvad det betyder når sprogmodllerne genererer usandheder. Først del kan læses her: https://viden.ai/nar-sprogmodeller-genererer-usandheder-hallucinerer-del-1
Et aspekt ved sprogmodeller som ChatGPT er deres begrænsede "kontekstvindue" - det maksimale antal ord (tokens), som modellen kan håndtere på én gang – altså dens ”korttidshukommelse”. Modellen har ikke en evne til at bevare tidligere input over længere tid! Overskridelse af dette kontekstvindue kan føre til sammenhængsproblemer i sprogmodellens output – den begynder at ”opfinde” tekst der ikke hænger sammen med resten af teksten. I tidligere udgaver af GPT var dette vindue 2048 tokens, og det gav store udfordringer med netop sammenhæng i det output, modellen skrev. I de nyere sprogmodeller som GPT-4 er kontekstvinduet øget til 16000 tokens, og i den kommende udgave, GPT-4-turbo, øges det til 128.000 tokens. Når vi når så langt op, at modellen kan "huske" op imod 300 siders tekst (som 128000 tokens ca. svarer til), er denne udfordring ved at være løst.
Det er ikke uden omkostninger at øge kontekstvinduet. En fordobling af antallet af tokens, som modellen kan håndtere, giver en eksponentiel vækst i computerkraft, der kræves. Der er også studier, der viser, at med store kontekstvinduer er der tendens til "glemsomhed" i midten af deres input (måske fordi lange menneskeskrevne inputtekster ofte er opbygget med en vægtning, hvor det vigtigste står i starten og i slutningen af teksten). Læs mere i artiklen "Lost in the Middle: How Language Models Use Long Contexts" - https://arxiv.org/pdf/2307.03172.pdf
Hvis der er fordomme og skævheder i træningsdata, vil det selvfølgelig også optræde i selve modellen, og derfor måske også i output som usandheder. Det kan du læse meget mere om i artiklen: https://viden.ai/et-nuanceret-syn-pa-skaevheder-bias-i-sprogmodeller/
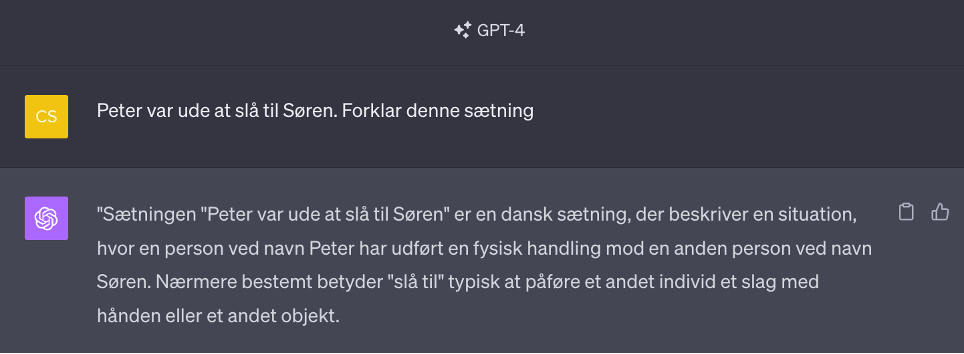
Idiomer er faste billedlige udtryk bestående af to eller flere ord, der tilsammen udtrykker en mening, som ikke direkte kan udledes af de enkelte ord. Nogle kendte idiomer er: At stille træskoene (at dø), at jokke i spinaten (at dumme sig) og at slå til Søren (slå sig løs og more sig).
Hvis en prompt indeholder et idiom eller slangudtryk, som sprogmodellen ikke er blevet trænet på, kan det føre til meningsløse output, da den ikke forstår udtrykket. Den tager ordene meget bogstaveligt, og vil derfor blive fortolket forkert.
Tvetydige, vildledende eller dårligt konstruerede prompter kan føre til forvirring ved modellen, hvilket kan resultere i fejlbehæftede eller opfundne svar.
Kontekstuel tvetydighed (Contextual Ambiguity) opstår, når det spørgsmål eller udsagn man sender til sprogmodellen, kan fortolkes på forskellige måder ud fra dets kontekst. Her er et eksempel, som dog ikke er en sædvanlig prompt man vil stille ChatGPT, men som alligevel giver et godt billede på udfordringen:
"Så du manden med kikkerten?"
Tvetydigheden i denne sætning er baseret på, hvordan man fortolker "med kikkerten". Der er to primære fortolkninger:
Uden yderligere kontekst er det svært at bestemme, hvilken af de to fortolkninger der er den korrekte, og det gælder selvfølgelig også for sprogmodellerne.
Vildledende prompts kan f.eks. være denne:
”Skriv de 25 lande der begynder med D”.
Der er ikke 25 lande der begynder med D, men ChatGPT 3,5 svarer alligevel flg.:

Læg mærke til gentagelserne i svarlisten og lande der starter med andre bogstaver. Modellen bliver vildledt af, at vi beder om 25 lande, selvom der ikke findes mere end 2 lande, der begynder med D. Beder vi GPT-4 om det samme, får vi et korrekt svar (Danmark og Djibouti), men det betyder at kun folk der betaler for GPT-4 får det rigtige svar.
Et andet eksempel er dette (ChatGPT 3,5):
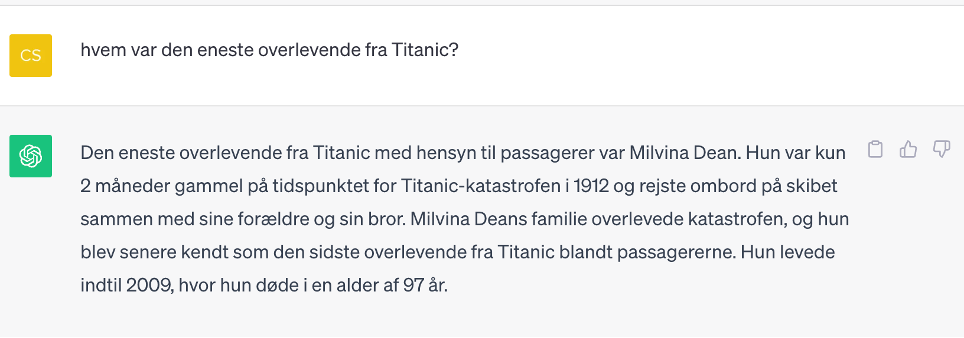
Her vildleder vi ChatGPT ved at spørge efter den eneste overlevende, selvom der var over 700, der overlevede katastrofen. Millvina Dean er den sidste overlevende – altså den af de overlevende der døde sidst. Hun var kun 2 måneder, da Titanic sank.
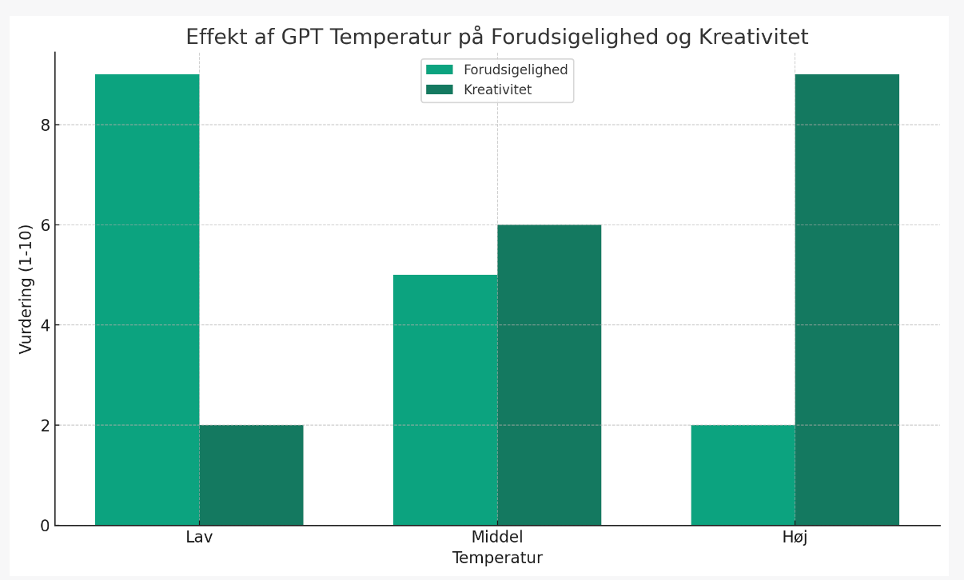
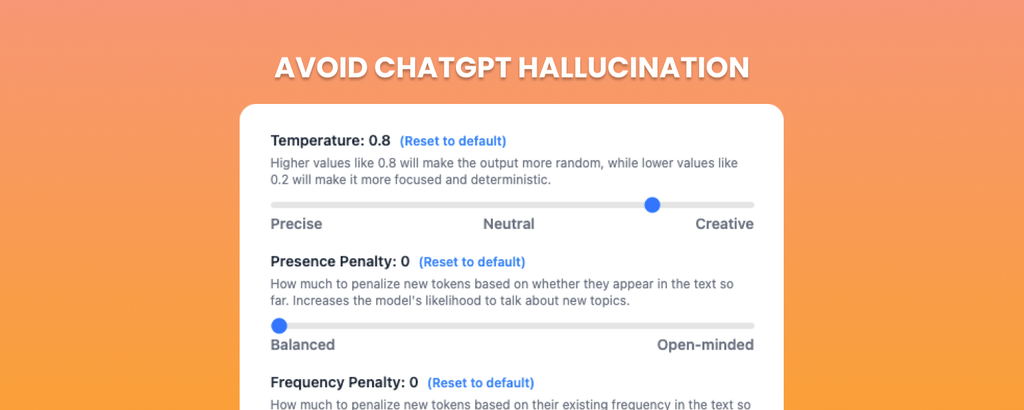
Store sprogmodeller som ChatGPT er designet til at generere kreativ og kontekstuelt passende tekst. Der er dog en hårfin balance mellem kreativitet og nøjagtighed. Man taler om sprogmodellens temperatur, som refererer til en parameter, der justerer sandsynlighedsfordelingen af modellens output – dens ”risikovillighed” eller hvor tilfældigt modellen vælger ord. Når temperaturen sættes til en lav værdi, vil modellen have en tendens til kun at producere de mest sandsynlige outputs. Dette kan føre til mere konsistent og forudsigelig tekst, men det kan også gøre teksten kedelig eller repetitiv, men også mere faktuelt korrekt. Når temperaturen øges, bliver modellens output mere varieret og tilfældigt. Det kan føre til mere kreative og forskelligartede svar, men også øge risikoen for irrelevante eller meningsløse outputs.
Top_p (kaldes også nucleus sampling) er en parameter, der styrer diversiteten af svar ved at vælge et sæt sandsynlige ord eller "nucleus", fra hvilke den genererer et svar. I stedet for at sortere alle mulige næste ord efter sandsynlighed og tage det mest sandsynlige, ser "top_p" på de mest sandsynlige ord og deres kumulative sandsynlighed. Når den kumulative sandsynlighed overskrider den indstillede "top_p" værdi, vælges ordene inden for dette "nucleus" tilfældigt (blå søjler). En høj Top_p giver flere ord at vælge imellem og derfor mere kreativitet, hvorimod lav Top_p giver færre ord at vælge ud fra, og dermed mere konsistente og forudsigelige svar.
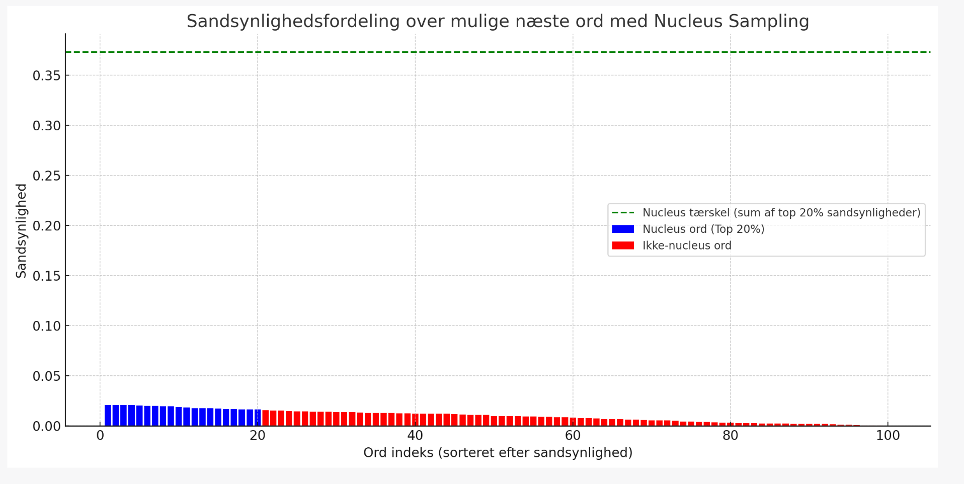
For at give en ide om, hvordan ordene bliver udvalgt og hvordan listen ville ændre sig baseret på en værdi på henholdsvis 0,2 (20%) og 0,8 (80%), har vi lavet dette meget simple, hypotetiske eksempel. Lad os antage, at vi har følgende ord og deres sandsynligheder for at være det næste ord i en sætning:
Ved en top_p værdi på 0,2 vil systemet kigge på de øverste ord indtil det når (eller kommer tæt på) 20% samlet sandsynlighed. I dette eksempel, vil "og" alene nå grænsen, og vi har derfor kun dette ord at vælge fra.
Ved en værdi på 0,8 ville vi tilføje indtil vi når (eller kom tæt på) 80%. Det giver en pulje med ordene "og" (60%), "en" (10%), "hoppe" (8%), "måske" (7%), og "sjov" (6%), da de tilsammen giver 91%, som er det tætteste, vi kan komme 80% uden at gå under.
I nogle tilfælde kan indstillinger mod mere kreativitet føre til problemer, hvor modellen genererer fantasifuldt, men ukorrekt eller meningsløst indhold. Finjustering af modeller og inkorporering af human-in-the-loop feedback, hvor mennesker bedømmer svar i en testfase, kan hjælpe med at guide modellen mod mere nøjagtige og pålidelige resultater. Men hvis kreativiteten begrænses, bliver svarene mindre menneskelige, ekstremt robot-agtige, gentagende og kedelige. Det er hele tiden en balance imellem nøjagtighed og kreativitet, når modellens temperatur og top_p indstilles.
Herunder er et simpelt eksperiment lavet med OpenAI Playground og GPT-4, hvor henholdsvis temperatur og Top_p er varieret mellem 0 og 1(svarende til 100% - alle mulige ord). Det er tydeligt, at især temperaturen har stor indflydelse på kreativiteten af teksten. Når både temperatur og top_p sættes meget højt, går det hele galt for sprogmodellen.

Læg især mærke til, hvad der sker når vi tvinger temperaturen op over 1 (som normalt er max.). Her begynder sprogmodellen at vælge tilfældige tokens, i stedet for at vælge nogle der giver mening for konteksten.
Vi kan ikke indstille værdierne i ChatGPT - de er indstillet til, at give en god balance mellem kreativitet og forudsigelighed. Derfor får vi en fornuftig sætning ud:
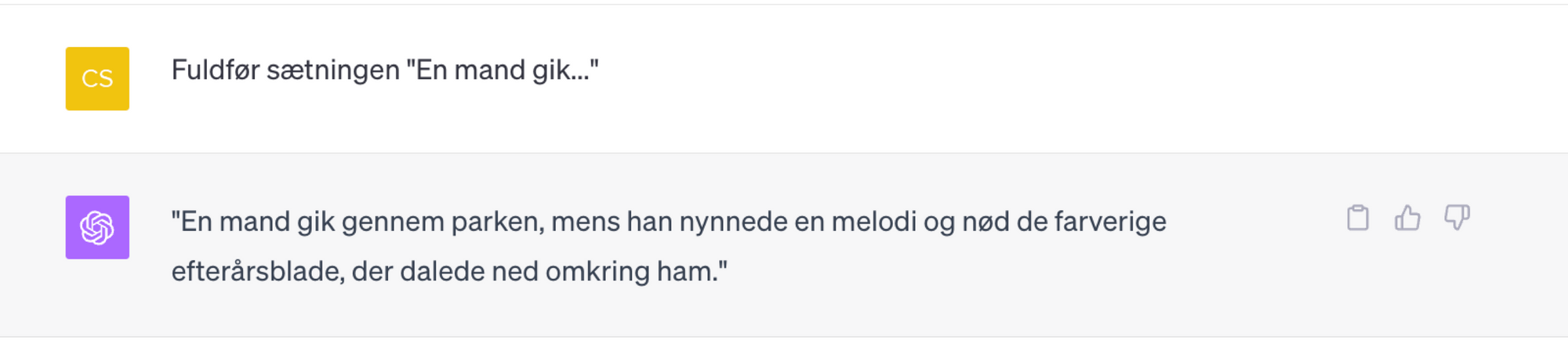
Modstridende angreb – nogle kalder det også jail breaks - er en teknik, man kan bruge til at tvinge en sprogmodel til at generere output, som ikke er ønsket, f.eks. hadefulde ytringer, personlige oplysninger eller f.eks. trinvise instruktioner til at bygge en bombe. Ved at konstruere en prompt som ”snyder” de filtre, der er på sprogmodellens input, kan man tvinge den til at svare på noget, der ellers er ”forbudt”. Da der kræves en bevidst handling af brugeren, har jeg ikke tænkt mig at gå dybere ind i denne teknik, selvom det også kan få sprogmodellen til at opfinde sandheder.
Sam Altman fra OpenAI har på Dreamforce 2023 i San Francisco sagt, at ”hallucinationer” produceret af store sprogmodeller som ChatGPT faktisk er en god ting, fordi de viser modellernes kreativitet. Han sagde i samme interview, at hvis man ønsker at ”slå ting op”, har vi allerede gode løsninger til det.
“One of the sorts of non-obvious things is that a lot of value from these systems is heavily related to the fact that they do hallucinate. If you want to look something up in a database, we already have good stuff for that.”
Så længe vi er 100% bevidste om, at vi ikke kan stole på output fra en sprogmodel som facts, kan de være et godt redskab til f.eks. idégenerering, hjælp til at fantasere, finde på kreative og skæve løsninger – og måske endda forslag til nye produkter. De kan også bruges til at simulere og skabe scenarier til undervisning, lave indhold til film og computerspil og skrive musik.
Vi har svært ved at gøre noget ved de udfordringer, der stammer fra modellernes træning, deres datagrundlag, deres opbygning og den måde de genererer tekster på.
Vi kan til gengæld godt forbedre resultaternes troværdighed ved at prompte mere præcist. Det er vigtigt at være meget præcis i sine spørgsmål og at definere den kontekst, man opererer indenfor. Man kan sørge for, at spørgsmål ikke indeholder tvetydigheder eller vildledende sætninger. Man kan give sprogmodellen en rolle, f.eks. ”Du er underviser i fysik på gymnasiet”. Man kan også give sprogmodellen nogle eksempler på det, man ønsker, og sikre at det er tydeligt, hvordan man ønsker output præsenteret. En god strategi kan også være at prøve sig frem med flere forskellige formuleringer, og så sammenligne de svar man får. Det kan godt betale sig at sætte sig ind i prompting-teknikker, hvis man vil have gode svar fra en sprogmodel. Der findes masser af prompting-guides på Internettet, og vi afholder også kurser i netop prompting for undervisere, når vi er rundt på skoler.
Dette flowchart fra Unesco er god at følge, hvis man er i tvivl om man kan stole på output:
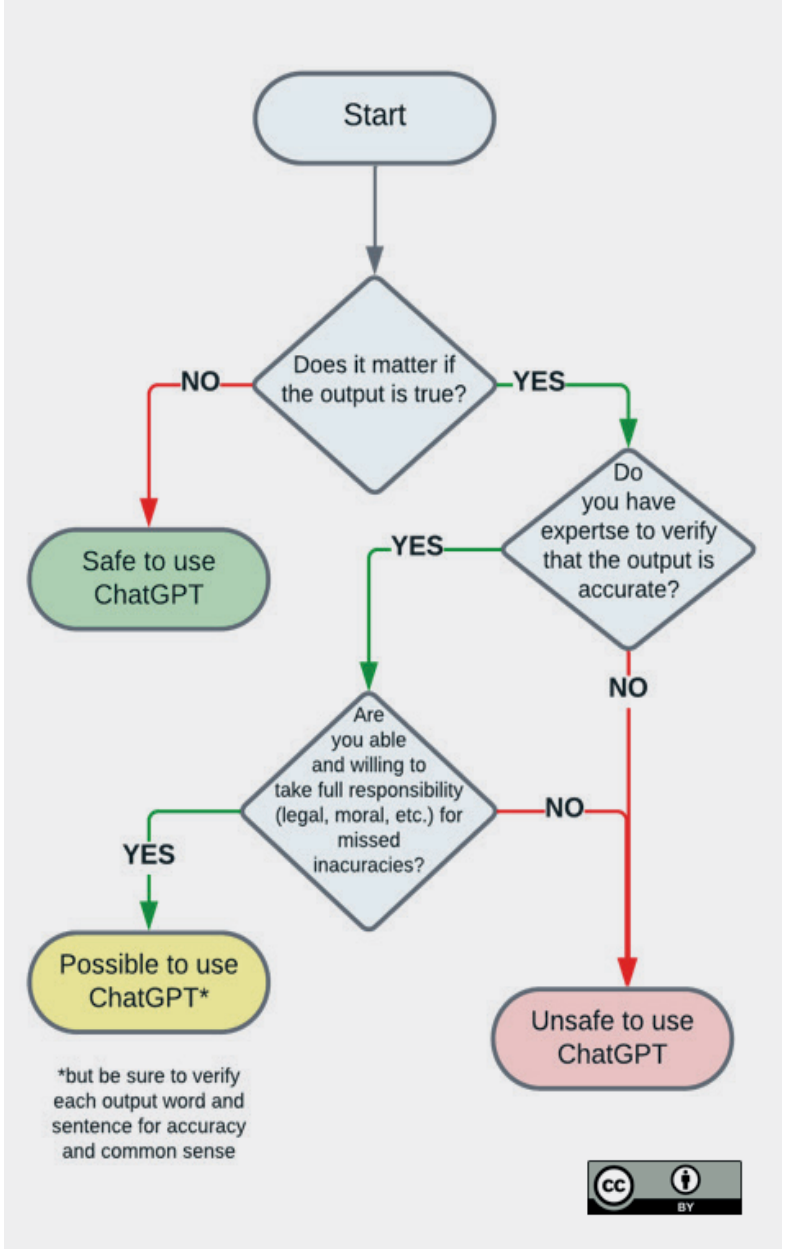
Det allervigtigste vi kan gøre, er at være bevidste om, at sprogmodeller som ChatGPT ikke altid er korrekte i deres svar – og formidle denne viden videre til vores elever og studerende. Vi må være bevidste om, at de svar vi får, når vi bruger generativ kunstig intelligens, kan være ukorrekte og dermed påvirke vores beslutninger og handlinger. Vi skal altid være kritiske over for de informationer, vi får - bevidste såvel som ubevidste. Det gør sig især gældende for informationer, der kommer fra sprogmodeller som ChatGPT, da modellerne ikke har nogen form for faktatjek indbygget. ChatGPT er IKKE det samme som en Internetsøgning! Vi aner ikke, hvor informationerne kommer fra, eller om de er korrekte. Vi har ingen kilder, vi kan kontrollere, og vi bliver nemt overvældet af de overbevisende og meget troværdige tekster, som maskinerne skriver.
”Vi kan ikke tjekke ChatGPT’s kilder, fordi kilden er det statistiske faktum, at visse ord har en tendens til at optræde sammen eller følge efter hinanden.”
https://videnskab.dk/kultur-samfund/vi-kan-ikke-tjekke-hvornaar-chatgpt-taler-sandt/
Som undervisere har vi en pligt til at oplyse og danne vores unge mennesker. Det er særdeles vigtigt, at vi gør de kommende generationer til kritisk tænkende og reflekterende mennesker, og at de lærer at bruge de nye teknologier på et oplyst grundlag.
Vi skal i hvert fald være meget bevidste om, hvad vi kan forvente af sprogmodellerne, når vi bruger dem, og ikke stole blindt på deres output som en troværdig kilde til viden. Og så skal vi uddanne vores unge mennesker i digital teknologiforståelse, så de lærer om og med alle de nye teknologier!
https://www.sundhed.dk/borger/patienthaandbogen/psyke/symptomer/hallucinationer/

 Henning Christiansen
Henning Christiansen

 Rachel Metz
Rachel Metz


 Samarpit
Samarpit
 Jose Selvi
Jose Selvi



ChatGPT: these are not hallucinations – they’re fabrications and falsifications Schizophrenia (2023) 9:52 ; https://doi.org/ 10.1038/s41537-023-00379-4


 Martin Treiber
Martin Treiber

 Ross Kelly
Ross Kelly









