Et nuanceret syn på skævheder -"bias" - i sprogmodeller

•
21 min læsetid

Anvendelsen af generativ kunstig intelligens, som f.eks. ChatGPT, bliver stadig mere udbredt – også i uddannelsesregi. Når vi inddrager ny teknologi i vores arbejde og uddannelse, er det meget vigtigt, at vi forstår dens muligheder og især dens begrænsninger. Store sprogmodeller (large language models) som ChatGPT, er et kraftfuldt værktøj, der rummer store muligheder, men som vi også skal være meget kritiske overfor. Der er nemlig potentielt en masse skævheder ”indbygget” i systemerne, som vi skal anerkende og være fuldt bevidste om, når vi bruger dem - og især når vi benytter dem til undervisning.
Denne artikel vil sætte fokus på en lang række af de mulige skævheder ved sprogmodeller og er tænkt som en ressource, man kan bruge, når man underviser i kritisk stillingtagen, kildekritik og ansvarlig brug af kunstig intelligens i undervisningen.
Når vi taler om skævheder, bruges begrebet ”bias” ofte – også på dansk. Ordet bias stammer fra engelsk, men er ifølge Dansk Sprognævn brugt som dansk ord allerede i 1953 og betyder ”forudindtagethed, tendens eller skævhed”.
Bias er også et begreb fra statistikkens verden, og her er ordet defineret meget mere præcist. Bias defineres her som forskellen mellem den (vedtagne) sande værdi af en kontrolprøve og gennemsnittet af et passende antal målinger på denne prøve. Statistikere taler tillige om varians, der er et mål for, hvor meget observationerne i observationssættet i gennemsnit afviger fra middelværdien. Hvis vi fx kigger på skud af dartpile mod en skive, vil målet være at ramme midten med alle pile. Lav bias vil være situationen, hvor alle pile sidder meget tæt sammen på centrum af skiven, mens høj bias repræsenterer den situation, hvor alle pile sidder tæt sammen, men et godt stykke væk fra midten. Variansen handler om, hvor stor spredning der er mellem de enkelte pile. Sidder alle pile i en serie tæt sammen, er der lav varians, mens høj varians beskriver situationen, hvor pilene sidder spredt over hele skiven.
I figuren herunder svarer det røde kryds til centrum af skiven (bulls eye), og de blå krydser repræsenterer dartpilenes position.
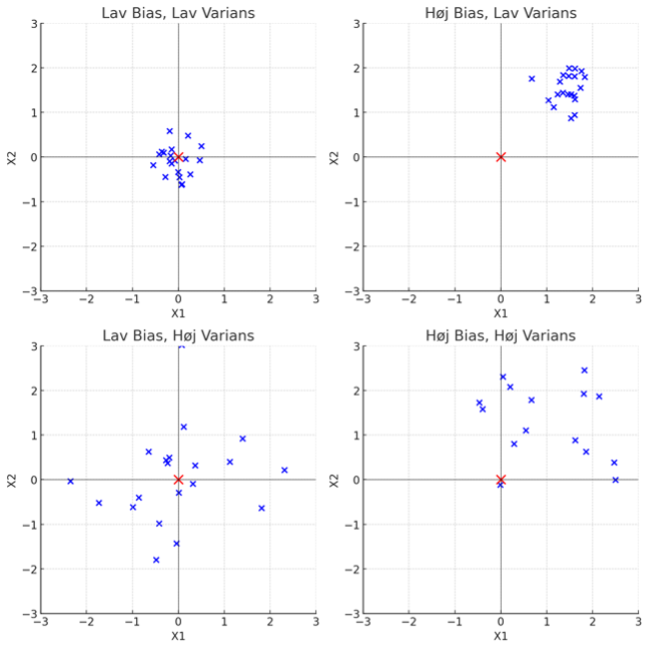
Hvis vi skal oversætte dette til sprogmodeller, svarer statistisk bias til, hvor nøjagtigt modellen forudsiger en tekst i forhold til det, vi vil forvente. Variansen svarer til, hvor konsekvent modellen svarer i forhold til det forventede. En statisk bias siger altså noget om, hvor god modellen er til at skrive ud fra de data, den er baseret på, og ikke hvor god den er i forhold til den verden, vi lever i!
Når der skrives og tales om bias i sprogmodeller som ChatGPT, handler det oftest om misforholdet mellem, hvad modellen skriver, og det vi ville ønske, den skriver (den ideelle verden set med den enkeltes øjne?). I virkeligheden handler det mere om, hvad vores forventninger er i forhold til de data, der er brugt til at træne modellerne med.
I denne artikel bruger jeg derfor kun ordet bias i forhold til betegnelserne af de forskellige skævheder, der kan opstå, fordi de fleste af begreberne kommer fra engelsk, men holder mig til begrebet "skævheder" andre steder.
Der findes en lang række potentielle skævheder, der kan optræde i og ved anvendelse af generative sprogmodeller. Mange af dem er "indbygget" i modellerne og er opstået i udvælgelsen af data og under træningen og implementeringen af dem, mens andre skævheder opstår, når vi bruger sprogmodellerne.
I denne artikel vil jeg komme omkring en række mulige skævheder og forsøge at forklare, hvordan de kan opstå.
Algoritmisk bias refererer til de skævheder, der er til stede i de data, der bruges til at træne de store sprogmodeller som f.eks. ChatGPT. Da disse modeller trænes på store menneskeskabte (eller måske er det bedre at sige menneskeligt udvalgte) datasæt (f.eks. tekster fra internettet), har de en tendens til at videreføre de uligheder, der er til stede i datasættene og dermed fastholde f.eks. stereotyper og diskrimination. Hvis data indeholder skævheder, vil modellerne sandsynligvis også gøre det. Størstedelen af de tekster, der er tilgængelige i verden, er skrevet af hvide vestlige mænd, og det i sig selv giver en skævvridning. Hvis en bestemt gruppe mennesker konsekvent er blevet portrætteret negativt i træningsdata, kan modellen udvise en lignende negativ vinkel i sine svar. Derfor vil sprogmodeller potentielt indeholde skævheder i forhold til køn, seksualitet, religion, race, kultur, alder, socioøkonomi, geografi m.m.

Et andet problem ved algoritmisk bias er, at træningen utilsigtet kan forstærke eksisterende fordomme. Dette skyldes, at modellerne kan “betragte”’ hyppigt forekommende meninger eller skildringer som "normale" eller "typiske". Da modellerne ikke har forståelse for kontekst, kan det føre til, at den genererer svar, der kan virke tendentiøse, selvom det ikke var hensigten.
Tilgængelighedsbias refererer normalt til den menneskelige tendens, at vi ofte baserer vores beslutninger og vurderinger af informationer ud fra den viden, der er let tilgængelig eller frisk i vores hukommelse. Det kan betyde, at mere fremtrædende eller nye begivenheder kan have en uforholdsmæssig stor indflydelse på vores beslutningstagning, selvom de måske ikke nødvendigvis er de mest relevante eller repræsentative.
Når vi omtaler tilgængelighedsbias i sprogmodeller, kan det stamme fra træningen på store mængder af offentligt tilgængelige data. Som et resultat heraf er modellen mere tilbøjelig til at favorisere indhold, der er lettere tilgængeligt (f.eks. populærkultur og aktuelle begivenheder), hvorimod den negligerer perspektiver og information, der er mindre udbredt online. F.eks. er træningsdata sandsynligvis baseret på frit tilgængelige tekster og ikke indhold, der er gemt bag betalingsmure. Det kan have indflydelse på adgangen til nogle perspektiver i træningssættene.
Tilgængelighedsbias kan også manifestere sig i den måde, sprogmodellen genererer svar på. Hvis visse typer informationer eller udtryksmåder er mere fremtrædende i træningsdataene, kan modellen have en tendens til at generere svar, der er i overensstemmelse med disse informationer. Det er ikke nødvendigvis en direkte skævhed i dataene selv, men snarere en ulighed i, hvordan modellen vælger at generere svar, baseret på de mest "tilgængelige" eller fremtrædende mønstre i dataene.
Tilgængelighedsbias i en sprogmodel kan skabe informationsbobler og ekkokamre, der forstærker eksisterende skævheder i stedet for at fremme forskellige perspektiver. Det kan også føre til misinformation om et givet emne, hvis den misinformation er lettere at få fat i end faktuelt indhold.
Repræsentationsbias i en sprogmodel refererer til den situation, hvor træningsdata ikke på korrekt vis repræsenterer det domæne, modellen er trænet til. Sprogmodeller, som ChatGPT, er trænet på et enormt stort datasæt, som i en ideel situation afspejler hele verden som domæne og derfor har en objektivitet og mangfoldighed, som sikrer, at alle aspekter af et emne er belyst. Hvis der f.eks. er emner, der ikke er repræsenteret i træningsdata, eller emnet ikke er belyst fra alle vinkler, kan det give repræsentationsbias. Hvis alle tekster i træningsdata om et bestemt emne er skrevet af én demografisk gruppe, vil der måske mangle perspektiver og meninger fra andre grupper. Når data alene kommer fra offentligt tilgængelige internetdata, som f.eks. Wikipedia, nyhedsartikler, internetfora og udvalgte bøger, vil der også ligge en repræsentationsbias i denne udvælgelse. Vi tillægger normalt peer-reviewede videnskabelige artikler højere værdi end frit indhold fra internettet. Sådanne videnskabelige artikler ligger oftest bag betalingsmure og er derfor nok ikke med i træningsdatasæt. Hvis træningsdata er gamle, og verden har ændret sig siden træning af modellen, kan modellen have en repræsentationsbias. (F.eks. ved ChatGPT ikke noget om krigen i Ukraine. Den kender kun til Ruslands invasion af Krim, da den blev færdigtrænet i september 2021).
Historisk bias kan også have indflydelse på sprogmodeller. Historiske tekster i træningsdata kan afspejle normer, værdier og holdninger fra de tidspunkter, de blev skrevet på. Disse kan være forskellige fra nutidens normer og kan derfor være skæve eller diskriminerende. Der kan også være situationer i historien, hvor visse demografier er blevet marginaliseret eller udeladt fra historiske registreringer. Desuden kan historiske kilder ganske enkelt indeholde faktuelle fejl eller forvrængede fortolkninger af begivenheder, hvorfor disse perspektiver afspejles i sprogmodellen.
Udvælgelsesbias opstår, når træningsdataene ikke er repræsentative for hele befolkningen eller målgruppen. Hvis visse perspektiver er underrepræsenterede eller udelukket fra træningsdataene, vil AI-modellen mangle den nødvendige "viden" til at generere upartisk og fuldstændigt objektivt indhold.
For eksempel, hvis træningsdataene primært omfatter data fra vestlige lande, kan sprogmodellen ikke producere nøjagtigt og kulturelt relevant indhold til ikke-vestlige målgrupper. Denne udeladelse fastholder samfundsmæssige uligheder og forhindrer modellen i at være en inkluderende og objektiv informationskilde. En anden udfordring kan være, at træningsdata kommer fra bestemte typer af kilder (f.eks. nyheds-websites, videnskabelige artikler eller sociale medier) Dette kan medføre en skæv forståelse baseret på de perspektiver og den stil, der er typisk for disse kilder. De fleste sprogmodeller, der er frit tilgængelige, f.eks. ChatGPT, er primært trænet på vestlige (amerikanske) tekster, hvorfor den vil have en tilbøjelighed mod vestlig (amerikansk) kultur og vestlige (amerikanske) værdier. Kina har derfor lavet sin egen sprogmodel og chatbot, kaldet Ernie Bot, der er lavet, så den er tro imod det kinesiske styre og dets værdier.
Gruppetilskrivningsbias opstår, når den generative kunstige intelligens (gælder for både sprogmodeller og billeddannende modeller) tilskriver specifikke karakteristika eller adfærd til en hel gruppe, baseret på nogle få individers handlinger. For eksempel kan modellerne forbinde negative egenskaber med specifikke etniciteter eller køn, hvilket fastholder skadelige generaliseringer og fordomme. For at undgå dette skal modellerne trænes på forskellige datasæt, der afspejler kompleksiteten og individualiteten af forskellige grupper.
Kontekstuel bias defineres som skævheder, der opstår, når man er afhængig af én bestemt kontekst for at få et korrekt svar. Det opstår, når sprogmodeller har udfordringer med at ”forstå” eller ”fortolke” konteksten af en samtale eller et prompt præcist. Misforståelse af sammenhængen kan føre til generering af upassende eller vildledende svar. Selvom de store sprogmodeller er i stand til at generere svar, mangler de en dyb forståelse af kontekst. Dette kan føre til svar, der teknisk set er korrekte, men som mangler nuance eller relevans i den givne situation.
ChatGPT har en meget begrænset "hukommelse", hvad angår tidligere interaktioner i en samtale. Den kan faktisk ofte ikke ”huske” tidligere samtaler (chatsessions). Hvis en bruger giver vigtig kontekst tidligt i en samtale, kan modellen ikke altid huske eller tage hensyn til denne kontekst i senere svar, hvorfor brugeren måske får et uventet svar. I modsætning til mennesker, der kan stille opklarende spørgsmål, hvis de er usikre på konteksten, genererer sprogmodeller alene svar baseret på den information, den har til rådighed. Det kan føre til misforståelser eller unøjagtige svar, hvis konteksten ikke er klart angivet i prompten. Hvis prompten mangler specifik kontekst i forhold til de data, der er tilgængelige, kan sprogmodellen ende med at give meget generaliserede eller stereotype svar. ChatGPT er bygget, så den stort set altid vil give et svar – uanset om svaret er rigtigt eller ej.
En mulig løsning på dette problem ligger lige så meget i finjusteringen af sprogmodellen ved menneskelig feedback, som i selve den ikke-superviserede træning på data. Når ChatGPT giver brugeren mulighed for at give feedback på, hvorvidt et svar er passende i forhold til en given prompt, ved thumbs up/thumbs down, er det bl.a. for at kunne minimere kontekstuel bias.
Sproglig skævhed omhandler de skævheder, der er indbygget i sproget selv eller i den måde, sprog bruges på. Disse skævheder kan afspejle og forstærke kulturelle, sociale eller kognitive fordomme. Hvis teksterne i træningsdata til sprogmodeller indeholder sproglige tendenser, vil modellen sandsynligvis også gøre det. For eksempel, hvis bestemte adjektiver ofte bruges sammen med bestemte substantiver (f.eks. "stærk mand" vs. "omsorgsfuld kvinde"), kan modellen genskabe disse associationer i sine outputs. Hvis træningsdataene indeholder stereotype eller fordomsfulde udtryk eller vendinger, vil sprogmodellerne også bruge eller bekræfte disse udtryk i sine svar. Nogle sprog har grammatiske strukturer, der kan afspejle kulturelle skævheder (f.eks. kønsbøjning af adjektiver eller substantiver). Hvis disse strukturer er skæve i træningsdata, kan modellen reproducere disse skævheder.
Hvis træningsdata er domineret af indhold på et bestemt sprog (f.eks. engelsk), kan modellen være bedre og mere nuanceret på det sprog, sammenlignet med andre sprog. Dette kan føre til en skævhed mod det dominerende sprog, og at indhold på andre sprog nedprioriteres. Derudover vil sprogmodeller ofte benytte sig af maskinoversættelse til engelsk og tilbage igen. Også her kan opstå skævheder.
Forankringsbias refererer til menneskers tendens til at stole for meget på det første stykke information, de modtager, når de træffer beslutninger. Efter at have modtaget en "forankring", justerer folk deres efterfølgende vurderinger og beslutninger, baseret på denne forankring, selvom den muligvis er irrelevant eller fejlagtig. Når en bruger stiller et spørgsmål til en sprogmodel, vil den bruge dette input som en forankring og generere et svar baseret på det. Hvis brugerens prompt indeholder en bestemt partiskhed eller vinkel, kan modellen have en tendens til at generere svar, der følger denne skævhed, selvom det ikke nødvendigvis er den mest objektive eller nøjagtige respons.
Mennesker kan genoverveje og justere deres første og umiddelbare vurderinger, efter at have modtaget mere information. Sprogmodellers svar er baseret på mønstre i træningsdata og den umiddelbare kontekst fra brugerens prompt. Det betyder, at sprogmodellen ikke aktivt "genovervejer" tidligere information i en chatsession, men snarere reagerer på den seneste forankring (prompt), den modtager.
Det er vigtigt at bemærke, at mens mennesker kan falde for forankringsbias på grund af kognitive skævheder, opstår denne form for skævheder i sprogmodeller primært på grund af dens interfacedesign og dens træningsdata. Modellen reagerer på det umiddelbare input, den modtager, og genererer svar baseret på dette alene.
Automatiseringsbias refererer til menneskers tendens til at stole overdrevent på automatiserede systemer og maskiner, ofte på bekostning af menneskelig dømmekraft og sund fornuft. Når mennesker stoler for meget på maskinerne, kan de overse fejl eller unøjagtigheder produceret af det automatiserede system og undlade at gribe ind, når det er nødvendigt.
Brugere kan have en tendens til at stole for meget på svar, genereret af sprogmodeller som ChatGPT, fordi de antager, at svarene altid er korrekte. Sprogmodeller virker jo enormt overbevisende og autoritative, når de skriver. Mange vil også betragte ChatGPT som en egentlig autoritativ kilde, selvom den ofte laver fejl og giver unøjagtige svar. På grund af den imponerende evne hos moderne sprogmodeller til at generere overbevisende og ofte korrekt lydende svar, vil mange brugere undlade at vurdere svarene kritisk eller søge yderligere bekræftelse (kildekritik). Når en prompt ikke er præcis nok, eller sprogmodellen ikke "kender til" det, der bedes om, så gætter systemet så kvalificeret, som det kan. Disse gæt baserer sig på statistik og sandsynlighed og vil derfor medføre skævheder - og dermed ofte helt forkerte svar!
Samtidig vil mange brugere blive for afhængige af kunstig intelligens evne til at generere indhold, besvare spørgsmål eller tage beslutninger, hvilket kan føre til en undervurdering af menneskelig ekspertise eller intuition. Derved kan vores evne til at være kritiske over for vores omverden blive påvirket. Det er vigtigt for brugere at være opmærksomme på automatiseringsbias, når vi interagerer med ChatGPT og andre automatiserede systemer. Selvom ChatGPT er en avanceret sprogmodel, er den langt fra fejlfri og bør ikke erstatte menneskelig dømmekraft. Brugere bør altid vurdere modellens svar kritisk og søge yderligere bekræftelse, når det er nødvendigt.
Bekræftelsesbias er en psykologisk mekanisme, hvor individer søger og husker information, der bekræfter deres eksisterende overbevisninger, mens de ignorerer viden, der udfordrer dem.

Hvis træningsdata, som sprogmodeller er baseret på, indeholder bekræftelsesbias fra menneskelige kilder (f.eks. skæve eller tendentiøse nyhedsartikler, blogs eller fora), kan denne skævhed blive indlejret i modellen. Dette betyder, at hvis en bestemt overbevisning eller et synspunkt er overrepræsenteret i træningsdata, kan modellen have en tendens til at generere svar, der bekræfter dette synspunkt.
Sprogmodeller evaluerer ikke information kritisk. Den genererer svar baseret på statistik og mønstre i træningsdata. Hvis en bruger stiller et spørgsmål med en bestemt vinkel, kan modellen have en tendens til at generere et svar, der bekræfter denne vinkel, fordi det afspejler de mønstre, den har set i træningsdata. På samme måde kan sprogmodeller have en tendens til at generere svar baseret på, hvad der er bedst repræsenteret i træningsdata, snarere end hvad der nødvendigvis er sandt eller objektivt. Dette kan føre til, at modellen bekræfter populære, men måske fejlagtige, overbevisninger.
Det er vigtigt at forstå, at mens mennesker kan falde for bekræftelsesbias på grund af kognitive skævheder, opstår denne form for skævhed i sprogmodeller primært på grund af dens træningsdata og den måde, den er designet til at generere svar på. Brugere bør være opmærksomme på denne begrænsning og tage modellens svar med et gran salt, især i kontroversielle eller følsomme emner.
Sprogmodeller som ChatGPT undergår en finjustering ved en proces, kaldet "forstærkende indlæring med menneskelig feedback" (reinforcement learning with human feedback - RLHF). I denne proces bruges mennesker, der vurderer modellens svar og derefter justerer modellen, så den svarer bedre i overensstemmelse med menneskelige normer og værdier. Den store udfordring er, at mennesker har vidt forskellige normer og værdier, bl.a. baseret på deres oprindelse. ChatGPT vil sandsynligvis svare i forhold til amerikanske etik, normer og værdier, da modellen er trænet af en amerikansk virksomhed i USA.
Der er helt sikkert flere mulige typer af skævheder ved sprogmodeller, end dem jeg har beskrevet i denne artikel. Tanken er ikke at lave en 100% utømmelig liste over mulige skævheder, der kan opstå, når man arbejder med generativ kunstig intelligens, men at sætte fokus på og oplyse om udfordringerne.
De fleste vil nok se en Google-søgning som et godt alternativ til at bruge ChatGPT til at finde information og skrive om et emne. Men er det så bedre og mere sikkert at bruge? Google personaliserer søgeresultaterne, baseret på brugerens tidligere søgehistorik, webhistorik, lokationsdata og andre personlige data. Dette betyder, at to forskellige brugere kan få forskellige søgeresultater for den samme søgning. Selvom dette kan forbedre relevansen af resultaterne for den enkelte bruger, kan det også skabe en "filterboble", hvor brugeren kun ser information, der bekræfter deres eksisterende overbevisninger. Google er en kommerciel virksomhed, på samme måde som OpenAI, der står bag ChatGPT er, og nogle af deres algoritmer vil prioritere betalte annoncer og andre kommercielle interesser over organisk indhold. De øverste (og dermed forankrende) resultater er oftest annoncer, som nogle har betalt for at få favoriseret! Algoritmer kan også prioritere indhold, der forventes at øge brugerengagementet, hvilket kan betyde, at mere sensationelt eller kontroversielt indhold bliver fremhævet frem for mere nuanceret eller objektivt indhold. Google anvender forskellige kvalitetskriterier for at vurdere troværdigheden og autoriteten af forskellige websteder. Man skulle tro, at det er godt, men det kan i nogle tilfælde føre til, at mindre kendte eller alternative synspunkter bliver nedprioriteret.
Der kan også opstå skævheder ved en Google-søgning, der udspringer fra brugeren. Brugere har en tendens til at søge efter emner og klikke på links, der bekræfter deres eksisterende overbevisninger, dvs. bekræftelsesbias. Også dette kan påvirke de personaliserede resultater, som brugeren vil komme til at se i fremtiden. Den måde, et spørgsmål eller en søgning formuleres på, kan påvirke de resultater, man får. For eksempel kan en søgning efter "fordelene ved X" give meget forskellige resultater i forhold til en søgning efter "ulemperne ved X". Mange brugere tjekker kun de første par resultater på en søgeside. Dette kan betyde, at de går glip af mere dybdegående eller alternative perspektiver, der måske ligger længere nede på siden, og oftest vil de kun se de søgeresultater, der er betalte! Brugere har også en tendens til at stole på kilder, de allerede kender eller anser for autoritative og kan overse eller undervurdere information fra mindre kendte kilder.
Den største forskel ved en Google-søgning og en ChatGPT-skrivning om et emne er, at man ofte selv skriver og sammensætter sit indhold fra flere kilder, når man søger på Google (human in the loop), hvorimod man lader ChatGPT skrive selv, uden at vide hvor informationerne kommer fra.
Alle mennesker er forudindtagede på en lang række måder. Når vi møder et nyt menneske, har vi en masse fordomme (bevidste eller ubevidste), som vi bedømmer personen ud fra. Vi lægger bevidst eller ubevidst mærke til overfladiske aspekter såsom køn, etnicitet, alder, udseende, påklædning, kropsudsmykninger osv. Disse oplysninger bruger vi intuitivt til at bedømme personen. Ofte vil vi også have nogle forventninger på forhånd, som kommer til at dominere vores indtryk af personen. Vi søger også sammenligning mellem f.eks. mennesker, vi kender og nye mennesker, vi møder. Vi kan have en tilbøjelighed til at tillægge nye mennesker i vores omgangskreds egenskaber ud fra vores forestillinger baseret på sammenligninger. Vi har også tendens til at kunne lide mennesker, der ligner os selv, eller som vi kender bedre, end nogle der er anderledes.
Mennesket vil have tendens til bekræftelsesbias, altså søge, fortolke og huske information på en måde, der bekræfter ens eksisterende overbevisninger eller hypoteser. Vi har en forankringsbias. Vi stoler mest på den første information, vi får. Vi ligger under for tilgængelighedsbias, hvor vi baserer vores vurderinger på information, der er let tilgængelig eller frisk i vores hukommelse, snarere end relevant information. Vi tillægger større troværdighed, og lader os påvirke mere af autoriteter eller eksperter, og vi har tendens til at gøre det samme som flertallet gør. Mange mennesker foretrækker at gøre, som de plejer, frem for at ændre eller nytænke, og de fleste favoriserer egne evner over andres. Og så er der Dunning-Kruger effekten: Jo mindre du ved om et emne, jo mere sikker er du i din sag!

Vi har også masser af kønnede skævheder i vores sprog. Dansk sprognævn har lavet en optælling, og i det danske sprog er der 187 ord, der ender på '-mand', mens kun 14 ord ender på '-kvinde'. De fleste er jobtitler, men det fortæller en masse om sproglig bias. Vi har tidligere skrevet om netop "kønsbias" og kunstig intelligens i artiklen "Kønsbias når generativ AI skriver tekster". Dansk Sprognævn vil rydde op i de kønnede betegnelser, når den ny udgave af retstavningsordbogen udkommer i 2024.
Alle disse skævheder og mange, mange flere vil være afspejlet i de tekster, vi skriver, og derfor overføres de til de sprogmodeller, der trænes på menneskeskabte tekster.
Vi kan også diskutere, om vi som undervisere er 100% fri for bias, når vi udvælger materialer til eleverne, og når vi underviser. Er alle undervisere fuldstændig fri for fordomme og præferencer? Måske er det netop, når forskelle mødes, at den gode læring opstår - i hvert fald så længe vi er bevidste om vores egen forudindtagethed. Og hvad betyder det så, i forhold til sprogmodellers skævheder?
Det allervigtigste, vi kan gøre, er at være bevidste om mulige skævheder, uanset om det er menneskers forudindtagethed, søgemaskinernes eller kunstig intelligens’ skævheder. Vi må erkende, at de kan påvirke vores beslutninger og handlinger på mange forskellige måder. Vi skal være kritiske over for de informationer, vi får - bevidste såvel som ubevidste. Det gør sig især gældende for informationer, der kommer fra sprogmodeller som ChatGPT, da modellerne ikke har nogen form for transparens. Vi aner ikke, hvor informationerne kommer fra, eller om de er korrekte. Vi ved ikke, hvordan datasættene er sammensat. Vi ved ikke hvorfor sprogmodellen vælger de ord den gør. Vi har ingen kilder, vi kan kontrollere, og vi bliver nemt overvældet af de overbevisende og meget troværdige tekster, som maskinerne skriver.
Som undervisere har vi en pligt til at oplyse og danne vores unge mennesker. Det er særdeles vigtigt, at vi gør de kommende generationer til kritisk tænkende og reflekterende mennesker, og at de lærer at bruge de nye teknologier på et oplyst grundlag. Oplysning og undervisning i teknologiernes mulige skævheder, behovet for kritisk tænkning, validering af informationer og sund skepsis er måske et godt sted at starte!
Vi skal i hvert fald være meget bevidste om, hvad vi kan forvente af sprogmodellerne, når vi bruger dem!
 Christina Lioma
Christina Lioma

https://medium.com/@savusavneet_28467/biases-in-machine-learning-ml-32b147492242
 Ken Knapton
Ken Knapton
https://rockcontent.com/blog/chatgpt-bias/
https://openwebtext2.readthedocs.io/en/latest/background/
https://arxiv.org/pdf/2005.14165.pdf
https://www.sciencedirect.com/science/article/pii/S266734522300024X
https://rockcontent.com/blog/chatgpt-bias/




 _jeremybaum
_jeremybaum Frederik Guy Hoff Sonne
Frederik Guy Hoff Sonne






 Melissa Heikkilä
Melissa Heikkilä

https://doi.org/10.48550/arXiv.2304.03738
 Paul Pu Liang, Chiyu Wu, Louis-Philippe Morency, Ruslan Salakhutdinov
Paul Pu Liang, Chiyu Wu, Louis-Philippe Morency, Ruslan Salakhutdinov






