Når sprogmodeller genererer usandheder – ”hallucinerer” - del 1

•
14 min læsetid

I forbindelse med store sprogmodeller som ChatGPT støder man ofte på begrebet hallucinationer - man taler om at modellerne ”hallucinerer”. Ligesom jeg skrev i artiklen om skævheder ved sprogmodeller som oftest omtales som bias (https://viden.ai/et-nuanceret-syn-pa-skaevheder-bias-i-sprogmodeller), har vi her igen et begreb som er upræcist og egentligt betyder noget andet. Nogle har foreslået begrebet konfabulation som erstatning for hallucination, men det er ikke meget bedre.
Det vi ser her, er et eksempel på antropomorfisme – det, at vi tillægger menneskelige egenskaber følelser eller intentioner til ikke-menneskelige enheder. Antropomorfisme stammer fra de græske ord "anthropos" (menneske) og "morphē" (form). Når vi bruger vendinger som kunstig intelligens, maskinlæring, sprogmodellen forstår eller tænker, modellens hukommelse og at den hallucinerer eller konfabulerer, tillægger vi menneskelignende træk til maskinerne – ligesom vi ofte ser kunstig intelligens afbildet som en humanoid robot. Læs også artiklen: https://viden.ai/etiske-aspekter-ved-chatbotter-i-undervisning-sindets-uhyggelige-dal/

En hallucination er, i medicinsk forstand, en sanseoplevelse uden en ydre påvirkning af sanseorganet. Det kan f.eks. være, at man hører og ser ting, som ikke eksisterer eller er uvirkelige, men som man opfatter som virkelige. Hallucinationer kan opstå ved sindslidelser som f.eks. psykoser og skizofreni, ved forandringer i hjernen eller efter indtagelse af stoffer som f.eks. LSD. Det er vigtigt, at hallucinationer er sanseindtryk, og at de kræver bevidsthed – noget sprogmodeller ikke har!
Konfabulation betyder, at en person ubevidst ”digter” det, vedkommende ikke kan huske og udfylder huller i sin hukommelse med fantasioplevelser, som personen fejlagtigt tror er sande. Personen vil være i stand til at svare hurtigt og detaljeret – men ukorrekt - på spørgsmål, som kræver genkaldelse af informationer fra hukommelsen. Disse opdigtede minder er ikke skabt bevidst for at vildlede eller lyve, men opstår ved visse hjernesygdomme, f.eks. demenslidelser eller hjernetraumer, hvor hukommelsen er påvirket. Konfabulation hænger sammen med fantasi, opfattelse og tro – igen noget som kun mennesker, og ikke sprogmodeller besidder.
Begge disse begreber er altså noget, der hænger sammen med den menneskelige hjerne og de fænomener, der knytter sig til den som f.eks. sanseindtryk, virkelighedsopfattelse, bevidsthed, fantasi og tro. Det kan være problematisk at bruge disse begreber som metaforer for sprogmodellernes fejl, da det kan forstærke antropomorfe forestillinger og gøre maskinerne mere menneskelige.
Men hvad skal vi så kalde det, når ChatGPT skriver noget, der er usandt eller ikke giver mening, og hvordan opstår det overhovedet? Nogle kalder det ”bullshitting”, andre siger at sprogmodellen lyver (igen et ord der refererer til en - bevidst - menneskelig handling).
Der er flere bud på ikke-antropomorfe begreber, bl.a. ”algoritmisk skrammel”, ”tendens til at opfinde fakta”, ”modellernes logiske fejl”, ”fabrikerede eller opfundne informationer”, bl.a. disse som kommer fra nedenstående 2 artikler. Man kan dog diskutere om ordet "opfinde" er antropomorft.

/cdn.vox-cdn.com/uploads/chorus_asset/file/24413225/Bard_Padding.png)
Når vi vælger at bruge ord, som vi normalt forbinder med noget menneskeligt, til at beskrive kunstig intelligens, hænger det bl.a. sammen med manglen på bedre begreber. Vi har endnu ikke et sprog, der kan forklare kunstig intelligens, og vi vælger derfor noget, vi kan forholde os til. Det har selvfølgelig den fordel, at de fleste mennesker til en vis grad kan forstå, hvad man mener, men det kan også være farligt og være med til at menneskeliggøre teknologierne i en uheldig grad.
Jeg har ikke selv et bedre bud i dette tilfælde, end at sprogmodeller sommetider kan generere output, der er faktuelt forkerte, usammenhængende, irrelevante, gentagende eller uventede. Til gengæld vil jeg forsøge at afdække nogle typer af uhensigtsmæssigheder, der ses ved store sprogmodeller, og forklare hvordan disse uhensigtsmæssigheder kan opstå. Denne artikel kommer ikke rundt om alle udfordringerne, men den forklarer de vigtigste og skulle gerne give en god baggrund for at forstå udfordringerne og deres mulige implikationer.
Hvis man læser det, der står skrevet med småt under input-feltet i ChatGPT, står der flg.:
”ChatGPT may produce inaccurate information about people, places, or facts.”

OpenAI skriver også følgende på deres hjemmeside:
”These models were trained on vast amounts of data from the internet written by humans, including conversations, so the responses it provides may sound human-like. It is important to keep in mind that this is a direct result of the system's design (i.e. maximizing the similarity between outputs and the dataset the models were trained on) and that such outputs may be inaccurate, untruthful, and otherwise misleading at times.”
For at forstå hvorfor der kan opstå uhensigtsmæssigheder som f.eks. fejlagtige svar og usandheder ved store sprogmodeller som ChatGPT, er det vigtigt at huske på, at modellerne er probabilistisk prædikative modeller. Der er altså tale om modeller, som forudsiger ord baseret på statistikker, og som er trænet på meget store datasæt bestående af tekster. I træningsfasen bliver ChatGPT udsat for enorme mængder af tekst, som den bruger til at lære mønstre og sammenhænge mellem ord. Det er vigtigt at bemærke, at modellen ikke har en forståelse af verden eller de begreber, den møder. Den lærer simpelthen at generere tekst baseret på de mønstre, den har observeret i træningsdata. Når sprogmodellerne skriver usandheder, er det i virkeligheden et produkt af, at de forsøger at "udfylde hullerne" i deres statistiske modeller ved at ”skabe” indhold, der opfylder spørgernes behov. I det følgende vil jeg se på, hvorfor der kan være huller i modellerne, og hvordan modellerne derfor skaber uhensigtsmæssige tekster. Modellerne bliver hele tiden bedre, men selv de bedste sprogmodeller vil sommetider lave fejl.
Sprogmodeller har ikke forståelse for eller bevidsthed om verden. De efterligner blot mønstre fra de data, de blev trænet på, så de kan generere svar, der lyder fornuftige og overbevisende, men sommetider er de meningsløse, unøjagtige eller opdigtede - i hvert fald i forhold til facts.
Hvis de data, som modellen er trænet på, ikke er repræsentative for den virkelige verden (f.eks. skævheder eller ”bias”) eller indeholder fejl (f.eks. misinformationer), kan modellen lære fejlagtige mønstre.
Hvis modellen bliver meget stor, som de nyeste GPT-modeller er, er der en risiko for et fænomen, der kaldes ”dimensionsforbandelsen” (Curse of Dimensionality). Størrelsen af træningsdatasættet skal vokse eksponentielt med antallet af dimensioner (features/parametre) i modellen for at opnå en tilstrækkelig og nøjagtig model. Med andre ord: Jo flere dimensioner data har, jo sværere bliver det at træne en præcis model, fordi rummet af mulige løsninger bliver større. Det kan medføre, at der sker en ”fortynding” af data i modellen, som gør det svært at finde sammenhænge og mønstre i dataene, hvis ikke der er tilstrækkelige træningsdata. Modellen kan altså blive så kompleks, at den ender med at blive mindre nøjagtig, sammenhængende eller kontekstuel relevant.
En anden vigtig ting at huske på, er at sprogmodeller som ChatGPT er ”pre-trained”, dvs. de er trænet én gang for alle, og bliver ikke trænet på ny. ChatGPT blev færdigtrænet i september 2022 (GPT-4 har i nyeste version også træningsdata fra 2023), og kender derfor ikke til ting der er sket efter denne dato. Modellerne har heller ikke nogen mekanismer til validering af rigtigheden af de svar, de giver os.
Når man taler om ”knowledge gaps” i forbindelse med træning af sprogmodeller som ChatGPT, handler det om, at der kan være områder, hvor modellen enten mangler nøjagtig information, eller hvor den har modstridende eller upræcise data. Disse mangler kan føre til, at modellen genererer information, der ikke er korrekt eller er baseret på fejlagtige antagelser. Hvis man prompter inden for et meget specifikt emne, er det ikke sikkert, at viden om det pågældende emne er inkluderet i træningsdata, hvorfor modellen sandsynligvis vil komme med et ”gæt”, med upræcise eller ukorrekte svar til følge. Hvis der i træningsdata er flere mulige vinkler på et emne (divergenser i kildedata), eller der er ukorrekte beskrivelser (misinformationer), vil modellen også risikere at svare ukorrekt eller vinklet i en uheldig retning. Husk på, at en meget stor del af træningsdata kommer fra Internettet, og en del fra ikke-validerede kilder. For at løse udfordringerne med manglende viden forskes der i metoder, hvor syntetiske data genereres for at supplere træningssættet, hvor der er mangler. Man kan også udnytte eksterne kilder til viden, såsom søgedatabaser på Internettet. Denne mulighed har ChatGPT version 4 (betalingsudgave), da den kan tilgå Internettet med Bing Search. Ved at integrere eksterne data i sprogmodeller, kan deres evne til at give præcise og informative svar samt evnen til at sige, at den ikke ved noget om emnet, forbedres.
Overtilpasning opstår, når en model bliver for kompleks og begynder at huske selve træningsdataene i stedet for at lære de underliggende mønstre. Det gør, at modellen klarer sig usædvanligt godt på træningsdata, men får problemer, når den præsenteres for nye ukendte data. Problemet opstår ved, at modellen får så mange detaljer, så den ikke formår at generalisere sin viden til forskellige sammenhænge. Det betyder, at modellen bliver for specialiseret til at generere tekst, der ligner træningsdata, på bekostning af evnen til at generalisere til nye, usete input. Denne overtilpasning kan resultere i, at modellen genererer tekst, der er plausibel-klingende, men faktuelt forkert eller ikke er relateret til inputtet. På figuren herunder ses forskellige måder at tilpasse en model til et datasæt bestående af punkter. Både ved den undertilpassede og den overtilpassede model, vil modellen få problemer med at tolke på et nyt datapunkt vi introducerer til den.
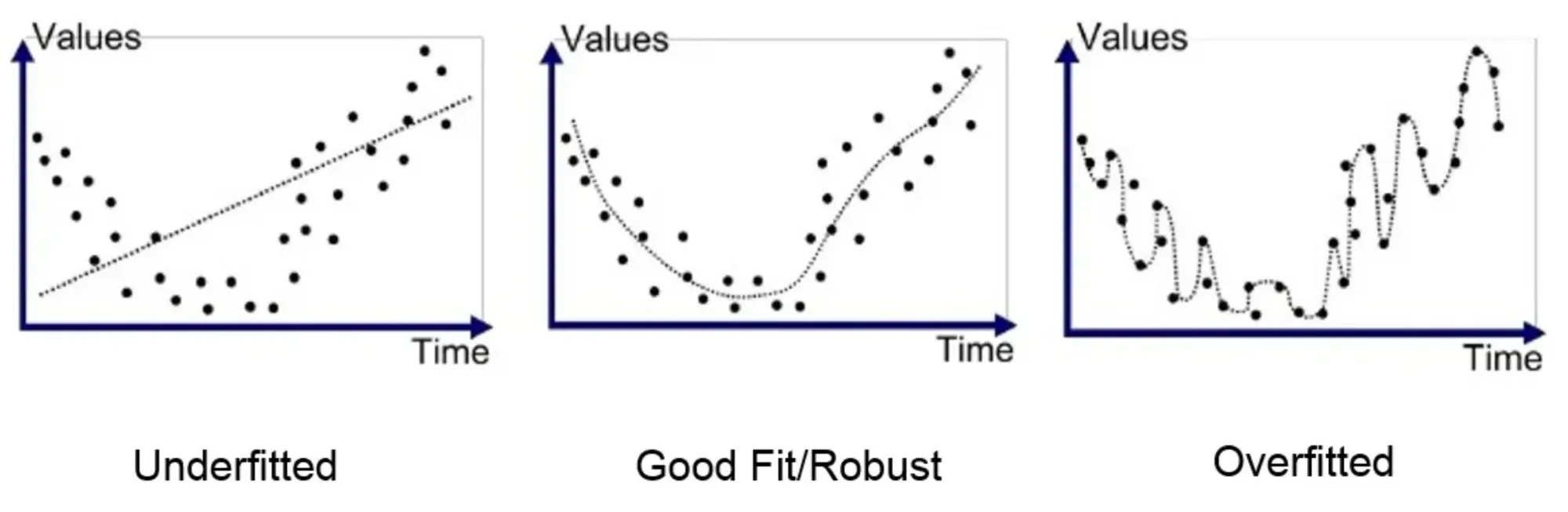
Forestil dig en sprogmodel, der har til opgave at generere filmanmeldelser. Modellen trænes på en masse filmanmeldelser, og efterhånden som træningen skrider frem, vil modellen utilsigtet begynde at indbygge specifikke sætninger, genretræk eller plotdetaljer fra træningsdataene i dens statistiske model – den overtilpasser sin model. Selvom dette kan resultere i meget overbevisende anmeldelser, der efterligner træningsdataenes stil, hvis den præsenteres for plot og genrer, den har mødt under træning, vil den til gengæld have store problemer (og måske begynde at nævne træk fra de genrer og plot, den kender fra træning), når den står over for nye genrer eller filmplot, den ikke er stødt på under træningen.
Et mere simpelt eksempel er flg.: Forestil dig, at vi træner en sprogmodel på en masse tekster om æbler. De fleste tekster indeholder, at æbler er røde, og modellen kommer til at overtilpasse til denne viden under sin træning. Hvis vi så spørger modellen om mulige farver på æbler, vil modellen måske svare at alle æbler er røde – selvom vi ved at æbler sagtens kan være gule og grønne også. Modellen svarer så usandt, på grund af en overtilpasning af data under træningen.
Overtilpasning kan opstå, hvis data har høj varians og lav bias, eller hvis modellen er for kompleks i sit design og samtidig har for lille træningsdatasæt.
Modsat overtilpasning findes også undertilpasning, hvor modellen bliver alt for simpel til at fange kompleksiteten i træningsdata. Hvis vi træner en sprogmodel på en masse tekster om æbler, deres sorter, farver, oprindelse, dyrkningsmetoder, anvendelse osv., og modellen der dannes, er undertilpasset, vil den ikke fange alle detaljerne fra træningsdata. Spørger man modellen om æbler, vil den måske svare meget generisk, at æbler er en frugt. Det er ikke direkte forkert, men unuanceret og uden detaljer.
På samme måde vil en filmanmeldelse fra en undertilpasset model, være usammenhængende, overfladisk og uden særlig meget info om filmens plot og genre. Undertilpasning kan opstå, hvis der er stor bias og lav varians i træningsdata, eller hvis modellen er for simpel og træningsdata for sparsomme (og måske for støjfyldte).
Undertilpasning er ret nemt at opdage ved test, og ses derfor ikke ved store sprogmodeller, hvorimod opstået overtilpasning kan være meget sværere at opdage, da modellen kan komme med meget overbevisende og detaljerede svar, som dog er usande.
I anden del af artiklen, som publiceres næste uge, vil vi se på lidt flere årsager til mulige uhensigtsmæssigheder, og hvordan de kan undgås. Vi kommer også ind på deres betydning når vi bruger sprogmodellerne i undervisning, og hvad vi skal være opmærksomme på.
https://www.sundhed.dk/borger/patienthaandbogen/psyke/symptomer/hallucinationer/

 Henning Christiansen
Henning Christiansen

 Rachel Metz
Rachel Metz


 Samarpit
Samarpit
 Jose Selvi
Jose Selvi



ChatGPT: these are not hallucinations – they’re fabrications and falsifications Schizophrenia (2023) 9:52 ; https://doi.org/ 10.1038/s41537-023-00379-4


 Martin Treiber
Martin Treiber

 Ross Kelly
Ross Kelly









