AI-søgemaskiner er blevet en del af hverdagen for danske elever, men er det en bekymrende udvikling? En ny undersøgelse viser, at 85 % af de studerende bruger ChatGPT til at søge information. Det kræver nye kompetencer at navigere i denne digitale virkelighed.
Den hastige udvikling af generativ kunstig intelligens (AI) har nu for alvor påvirket den måde vi søger informationer på. Google og OpenAI har hver især udviklet nye søgemaskiner - henholdsvis Google AI Search (endnu ikke tilgængelig i EU) og Search GPT. Begge virksomheder hævder, at deres teknologier fundamentalt vil ændre, hvordan vi finder og bearbejder information. Disse teknologier lover at gøre adgangen til viden lettere og mere effektiv, ved at levere opsummerede svar med kildehenvisninger.
I en tidligere artikel på viden.ai har Per skrevet flg.:
OpenAIs ChatGPT search er nok den vej, vi fremover skal søge efter information på nettet.
Netop denne kommentar har fået en del opmærksomhed, da flere akademikere afviser påstanden. Virkeligheden på gymnasierne er desværre, at eleverne i høj grad tager de nye AI-søgemaskiner til sig. Jeg har allerede set eksempler på elever der stort set ikke Googler mere - de spørger ChatGPT search og synes det er fantastisk! Og det stopper ikke der. OpenAI tilbyder nu en søgeudvidelse til Google Chrome-browseren, så deres ChatGPT Search kan blive din nye standardsøgemaskine.
Udfordringer med AI-søgemaskiner
Hvis man installerer denne udvidelse, er det ikke længere synligt, om man bruger ChatGPT Search eller en almindelig søgemaskine! Eleverne vil lynhurtigt glemme, hvordan deres søgeresultater dannes.
Herunder kan du se, hvordan OpenAI præsenterer sine AI-funktioner i desktopappen til macOS. Bemærk, hvordan ChatGPT Search bruges til at finde faktuelle oplysninger uden en dybere kildekritik.
Selvom disse nye “søgemaskiner” på overfladen ser smarte ud, rejser de også betydelige spørgsmål om kvaliteten og pålideligheden af de informationer, de genererer, hvilke websites de egentlig har adgang til, og vigtigst af alt - kan man overhovedet tale om det som viden?
Det Kongelige Bibliotek har også lanceret en såkaldt “AI Research Assistant”, der fungerer på samme måde. Her stiller man et spørgsmål og får et svar baseret på fem udvalgte kilder.
Dit spørgsmål omdannes til en forespørgsel, som søgemaskinen forstår ved hjælp af en stor sprogmodel (i øjeblikket GPT 3.5). Søgemaskinen identificerer derefter relevante dokumenter. Den rangordner dem efter, hvor godt de kan besvare spørgsmålet, og ved hjælp af den store sprogmodel skaber den et svar ud fra de fem kilder. På grund af de store sprogmodellers natur er svarene på det samme spørgsmål ikke altid de samme. Der kan være mere end ét muligt svar og forskellige ressourcer, der er relevante. Hvis du ikke er tilfreds med dine svar, skal du bruge knappen "Prøv igen".
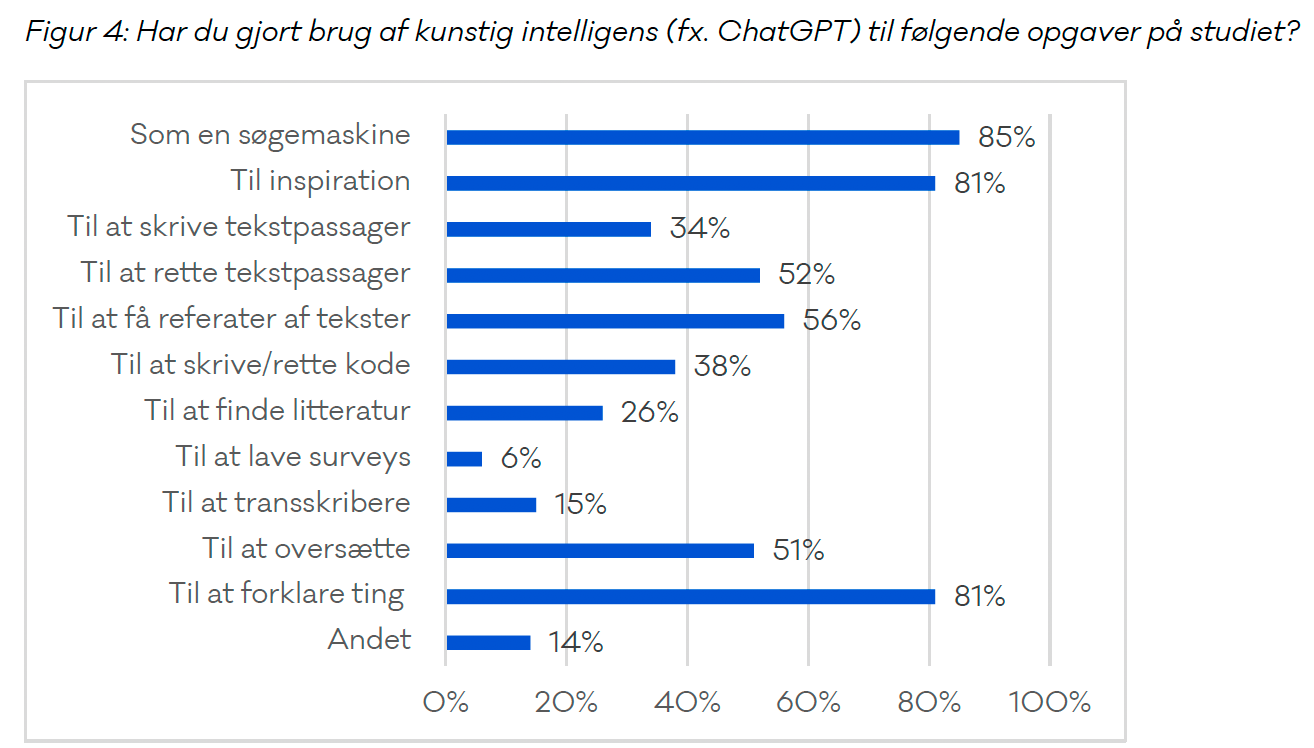
Den største udfordring er, at flertallet af elever og studerende (og i det hele taget flertallet af mennesker) ikke kan gennemskue teknologiernes udfordringer og begrænsninger. De ser det som en kæmpe hjælp, der kan effektivisere vores adgang til viden. En undersøgelsen fra DJØF fra oktober 2024 viser, at 85% af de adspurgte studerende har brugt den almindelige ChatGPT som søgemaskine. Undersøgelsen er lavet før Search GPT blev lanceret. Det understreger bare pointerne i denne artikel.
I uddannelsesverdenen står vi over for en meget vigtig opgave, nemlig at hjælpe vores elever og studerende med at navigere i dette nye og komplekse informationslandskab. Vi skal hjælpe med at udvikle de nødvendige kompetencer hos eleverne, så de bliver i stand til at vurdere kvaliteten af svar, uanset om de kommer fra mennesker, generativ kunstig intelligens, traditionelle Internetsøgemaskiner eller kilder som bøger og artikler, og ikke mindst bliver i stand til at vælge de rette informationskilder alt efter opgavens karakter.
Et af de centrale spørgsmål, som de nye AI-søgemaskiner rejser, er spændingsfeltet mellem syntetiseret og valideret viden. Ved at sammenfatte informationer fra flere kilder og præsentere dem i et letfordøjeligt format, kan disse nye værktøjer give indtryk af, at de leverer autoritativ viden. Men denne syntese medfører en betydelig risiko for fejlagtige informationer (hallucinationer), at vigtige nuancer går tabt, at kontekst udelades, og at potentielt upålidelige kilder vægtes lige så højt som kilder af høj kvalitet. Det sammenholdt med automatiserings-bias, som gør at vi mennesker har tilbøjelighed til at stole på maskiner, er en potentiel farlig cocktail.
Emily Bender, som er professor i lingvistik på University of Washington, skrev fornyligt denne kommentar om AI-søgemaskiner, som illustrerer en af udfordringerne ganske udmærket:
Furthermore, a system that is right 95% of the time is arguably more dangerous tthan one that is right 50% of the time. People will be more likely to trust the output, and likely less able to fact check the 5%.
...Instead you get an answer from a chatbot, even if it is correct, you lose the opportunity for that growth in information literacy.
Vi har som undervisere en vigtig opgave i, at lære vores studerende og elever at skelne mellem forskellige typer af viden, hvornår informationer ikke nødvendigvis er viden - og ikke mindst hjælpe dem med at indse værdien af solid, velunderbygget viden. Vi må lære dem at modstå fristelsen til at bruge syntetiserede AI-svar ukritisk og i stedet engagere sig i den krævende, men nødvendige proces med selv at søge og vurdere kilders kvalitet.
AI-søgemaskiner i et videnskabsteoretisk perspektiv
Set fra et videnskabsteoretisk perspektiv, rejser de nye AI-drevne søgeværktøjer fundamentale spørgsmål om selve karakteren af viden og videnskabelig praksis. Videnskabelig viden ses som resultatet af en omhyggelig, systematisk proces, hvor hypoteser testes, resultater dokumenteres, og konklusioner underkastes kritisk granskning af fagfæller. Gode nyhedskilder er journalistisk bearbejdede og fact-tjekkede og underlagt presseetiske retningslinjer. Men når svar genereres af uigennemskuelige algoritmer, der syntetiserer information på måder, vi ikke fuldt ud forstår, udfordres disse principper.
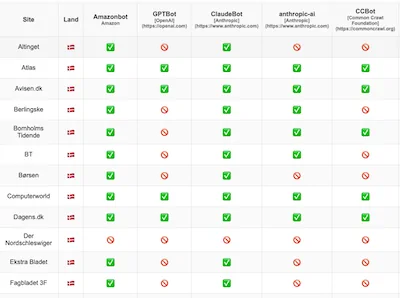
En særlig udfordring med nyhedskilder er, at mange store og troværdige nyhedsmedier har blokeret for adgang til disse AI-søgemaskiner. En simpel test har vist, at stort set ingen af de seriøse danske nyhedsmedier dukker op som kilder ved søgning! På viden.ai har vi derfor lavet en robot, der tjekker hvilke danske aviser der blokerer og hvilke der tillader, de forskellige AI-tjenester adgang. Listen, som opdateres automatisk, kan ses her:
Se hvilke danske nyhedsmedier der blokerer for AI-tjenester
Et andet centralt problem er den epistemiske ugennemsigtighed, som kendetegner mange AI-systemer. Selvom ChatGPT Search, Google AI Search og andre AI-drevne søgemaskiner giver kildehenvisninger, forbliver selve processen med at udvælge, vægte, fortolke og sammenholde disse kilder skjult. Vi kan ikke spore, hvordan konklusioner er nået – en situation, som er i fundamental modstrid med videnskabelige idealer om transparens og kritisk undersøgelse. Hvis vi ikke fuldt ud kan forstå eller genskabe den proces, hvorved et svar er genereret, hvordan kan vi så have tillid til svarenes validitet?
Disse spørgsmål bliver særligt vigtige, når vi overvejer risikoen for, at AI-modeller kan forstærke eksisterende bias eller fremhæve misvisende korrelationer som kausale sammenhænge. Desuden er der en risiko for, at AI-systemer i deres bestræbelser på at levere klare, utvetydige svar undlader at gengive den usikkerhed og nuance, der kendetegner meget viden. Videnskab giver sjældent endegyldige sandheder, men er snarere et område præget af sandsynligheder, antagelser, forbehold samt løbende debatter og uenigheder. Hvis AI-genererede svar præsenterer videnskabelige konklusioner som 100 % endegyldige fakta, kan det give et forvrænget billede af videnskabens natur.
Udvikling af kritisk 'AI-literacy' og informationskompetence
Vi må derfor undervise i, hvad der tæller som gyldig viden, og hvordan vi vurderer dens kvalitet. Vi må lære elever og studerende at værdsætte gennemsigtighed, at acceptere usikkerhed, og at se viden som en proces der ændres over tid. Vi skal fremelske en sund skepsis over for ethvert system, der hævder at tilbyde hurtige, endegyldige og eviggyldige svar, og i stedet styrke elevernes evne til selv at engagere sig med primære kilder og faglige diskussioner.
I lyset af disse udfordringer bliver kildekritik, informationskompetencer og, ikke mindst, teknologiforståelse mere afgørende end nogensinde. Vores elever har brug for redskaber til at navigere i et stadig mere komplekst informationslandskab, hvor grænserne mellem menneskeskabt og AI-genereret viden bliver stadig mere flydende. I stedet for kun at fokusere på at evaluere individuelle kilders troværdighed, må vi også lære eleverne at vurdere de processer, der ligger bag den måde, information syntetiseres og præsenteres. De må lære at stille spørgsmål som: Hvilke kriterier bruger dette system til at udvælge og vægte kilder? Er der potentielle bias indlejret i systemets algoritmer? Hvordan kan vi verificere de påstande, der fremsættes? Og det vigtigste – er dette overhovedet en kilde, eller har vi med en syntetiseret tekst at gøre?
Vi bør måske lære vores elever at se ethvert svar, uanset hvor det kommer fra og hvor autoritativt det virker, som en hypotese der skal testes, snarere end en etableret sandhed.
Derudover må vi hjælpe eleverne med at udvikle en nuanceret forståelse af, hvornår forskellige informationskilder er passende. Mens syntetiserede svar fra AI kan være nyttige til at få et hurtigt overblik over et ukritisk emne, er de måske ikke tilstrækkelige, når opgaven kræver dybdegående analyse of forståelse. Omvendt kan tidspresset i nogle situationer gøre brugen af traditionelle akademiske kilder upraktisk, hvorved AI-svar kan være et acceptabelt kompromis, så længe man er klar over konsekvensen.
Kunsten at stille de rigtige spørgsmål
En ting er at være kildekritisk, overveje kilders kvalitet og egnethed, om de er aktuelle og opdaterede, eller potentielt forældede? Men hvordan vurderer man egentligt om et svar er godt? Dette spørgsmål er ikke kun relevant i forhold til AI-drevne søgninger, men i det hele taget når man søger information for at få svar på et spørgsmål.
Nogle af de ting man kan undersøge er, om svaret overhovedet svarer på det stillede spørgsmål – om det overhovedet er relevant! Er svaret velunderbygget og præsenterer det en afbalanceret og nuanceret behandling af emnet, eller favoriserer det bestemte perspektiver på bekostning af andre? Bygger det på solide logiske ræsonnementer og empiriske beviser, eller indeholder det huller, springende eller cirkulær argumentation? Anerkender det områder med usikkerhed, debat eller modstridende fortolkninger, eller præsenterer det komplekse spørgsmål som simple og entydige?
Kritisk vurdering handler ikke kun om at evaluere de svar, vi modtager - det handler også om at stille de rigtige spørgsmål til at begynde med. Effektiv udnyttelse af generativ kunstig intelligens og forskellige søgemaskiner, AI-drevne eller traditionelle, afhænger af evnen til at formulere spørgsmål, der er klare, specifikke og egnet til den specifikke søgemetode. Et for bredt eller uklart spørgsmål vil sandsynligvis give et overfladisk eller forvirrende svar, mens et for snævert eller ledende spørgsmål kan resultere i et svar, der blot bekræfter spørgerens eksisterende antagelser. Når vi stiller et spørgsmål til et andet menneske, vil et uklart spørgsmål oftest medføre et modspørgsmål f.eks. "hvad mener du med det?" eller "jeg forstår ikke helt...". En sprogmodel vil "bare" generere et svar på det stillede spørgsmål, hvorfor det måske vil være forkert eller upræcist. Man kan sagtens stille uddybende spørgsmål til AI-søgemaskinen, men det kræver at man kan gennemskue nødvendigheden af det, og det kan være svært når man som elev er usikker eller fagligt udfordret.
For at imødekomme dette bør vi lære vores elever og studerende strategier for effektiv spørgsmålsformulering til forskellige informationskilder. Det omfatter bl.a. teknikker som at bryde et komplekst spørgsmål ned i dets bestanddele, identificere emnespecifikke nøglebegreber, overveje spørgsmålet fra flere vinkler eller perspektiver, og iterativt tilpasse og forbedre spørgsmålet baseret på de svar, der genereres. Ved at lære kunsten at stille gode spørgsmål kan vi blive mere effektive brugere af disse teknologier, og i stand til at anvende dem som kraftfulde værktøjer til undersøgelse og læring. For at kunne stille gode og effektive spørgsmål, skal man desuden beherske en solid grundfaglighed inden for det felt, man vil undersøge!
Konklusion
Vi skal ikke afvise AI-søgeværktøjer fuldstændigt, men lære at udvikle en strategisk og især kontekstafhængig tilgang til deres anvendelse. Ved at kunne reflektere over styrker og begrænsninger ved forskellige informationskilder og vælge dem fornuftigt i forhold til den konkrete opgave, kan vi styrke vores informationskompetence og kritiske sans.
Gennem uddannelse skal der udvikles en 'kritisk AI-literacy' og måske vigtigere; en stærk informations-litteracy. Elever og studerende skal ikke blot lære at bruge AI-teknologier, men også at forstå de underliggende mekanismer, etiske implikationer og potentielle bias. De skal kunne vurdere AI-genereret information kritisk, bruge AI reflekteret som et værktøj til læring og problemløsning, på en socialt ansvarlig måde.- og måske det vigtigste: lære hvornår AI-værktøjer giver mening at bruge, og især hvornår de bør fravælges. Kort sagt skal vi uddanne oplyste, kritiske og etiske brugere af forskellige informationskilder.
Kilder:
Envisioning Information Access Systems: What Makes for Good Tools and a Healthy Web? Chirag Shah and Emily M. Bender: