Etiske aspekter ved brug af chatrobotter i undervisningen – Fokus på privatliv

•
5 min læsetid

På Viden.ai har vi efterhånden brugt meget tid på at skrive om, hvordan læreren kan undersøge, hvorvidt en tekst er skrevet af chatrobotterne eller af eleven selv. Plagiat og snyd er det, som alle på tværs i uddannelsessystemet snakker om for tiden - lige fra den enkelte underviser, der dagligt føler sig presset af elevernes nye typer af afleveringer, til institutioner, der helt vil forbyde den kunstige intelligens i undervisningen. Men denne diskussion er med til at fjerne fokus fra det, som er mere interessant at debattere, nemlig de etiske aspekter ved teknologien. Her kan man stille en række spørgsmål som f.eks.: Hvorfor skal vi arbejde med den kunstige intelligens i undervisningen? Hvornår skal vi inddrage den? - Og ikke mindst: Hvornår skal vi ikke give mulighed for at bruge teknologien?
Vi vil i denne og i kommende artikler adressere en række etiske problemstillinger med henblik på anvendelsen af de nye sprogmodeller i undervisningen. Vi ønsker at lægge op til diskussion i klassen, på lærerværelset, i ledelsen og gerne i Undervisningsministeriet. For hver artikel vil vi derfor stille en række spørgsmål, som man selv kan arbejde videre med. Der vil ikke være noget rigtigt eller forkert svar, men udelukkende spørgsmål, der gerne skulle hjælpe med at få startet diskussionen om etiske dilemmaer ved at bruge den kunstige intelligens i undervisningen.
I øjeblikket er GPT-3.5 trænet i data, som er frit tilgængelige på nettet, og det kan eksempelvis være tekster fra Wikipedia, bøger og gennemtrawling af internetsider. Det betyder, at der kan være indhold fra sociale medier, personlige websteder og chat- eller endda e-mail-beskeder, hvis de er offentligt tilgængelige. En stor udfordring er, at disse data er indsamlet fra engelske kilder, og dermed vil der naturligt ske en skævvridning af informationer, når vi skriver til GPT-3.5 på dansk. Kun omkring o,45% menes at være dansk indhold.
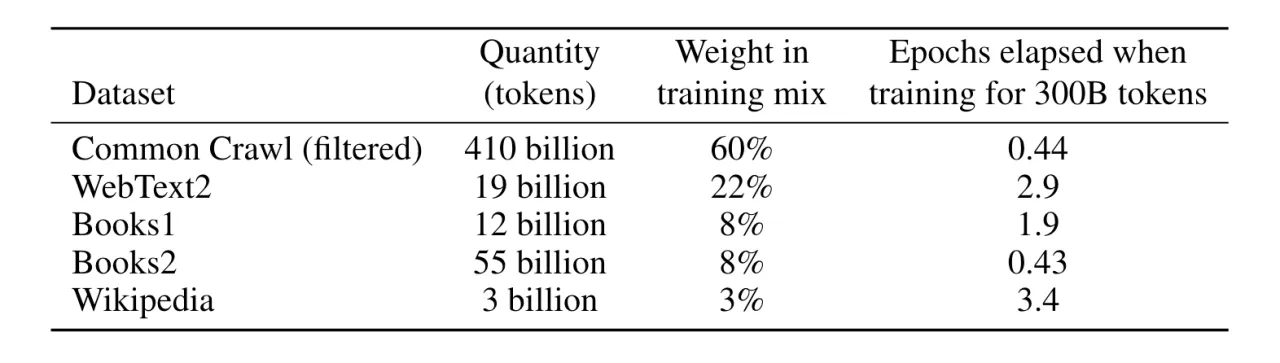
I øjeblikket anvender ChatGPT et datasæt, der lukkede ned i sommeren 2021, mens Bing både bruger selvsamme datasæt og benytter informationer fra Bing søgemaskinen. Det er dog ikke helt klart, hvilke data sprogmodellerne har brugt til deres træning, men vi ved, at de nogle gange indeholder identificerbare personlige oplysninger. Det er både navne, e-mails, telefonnumre, adresser og kontoer på sociale medier. Nogle gange møder vi disse data i det output, som kommer fra sprogmodellerne.
Harvard-professor Shoshana Zuboff mener, at sprogmodellerne er en del af den overvågningskapitalisme, som i de senere år har indsamlet store mænger data om brugerne, kun med det formål at tjene penge på dem. Derfor bør vi også være ekstra opmærksomme, når vi anvender teknologien i undervisningen, eftersom vi er med til at skabe en afhængighed hos eleverne, samtidig med at vi giver data om eleverne til store amerikanske tech-giganter.
Derfor skal man ikke indtaste personfølsomme oplysninger, lade fx ChatGPT svare på interne mails, vurdere elevernes opgaver, udarbejdelse af CV, sortering af elevlister eller andre typer af informationer, som vi ikke normalt deler offentligt. I onlineversionen af ChatGPT, bliver alle dine indtastninger koblet sammen med din email og dit telefonnummer, og disse informationer kan bruges til at forbedre tjenesten, men ikke til at træne modellen - endnu. Vi ved dog ikke, om OpenAI er ved at træne en ny version, men eftersom det er en Generative pre-trained transformer, lærer den ikke af de inputs, den modtager. Den har glemt alt næste gang, man skriver med den.
En lakmustest bør dog være: Hvis man ikke kan skrive informationerne på et postkort, så kan man ikke skrive dem på en chatbot.
Derfor skal vi netop have en etisk diskussion om, hvordan vi håndterer problemstillingerne om privatliv i forbindelse med brugen af sprogmodellerne, og vi skal kunne sige fra, hvis vores grænse er nået.

 Glyn Moody
Glyn Moody