Udfordringerne ved ChatGPT som søgemaskine i uddannelsessektoren
OpenAI har for nylig lanceret ChatGPT search, hvilket har vakt stor opmærksomhed, da man nu kan søge direkte i sprogmodellen.

•
9 min læsetid

OpenAI har for nylig lanceret ChatGPT search, hvilket har vakt stor opmærksomhed, da man nu kan søge direkte i sprogmodellen.
Funktionen fungerer som et alternativ til Google Search og Microsoft Bing. Men mens tech-giganterne kæmper om, hvor og hvordan vi søger efter informationer på nettet, mener jeg, at vi bør være lidt forsigtige med at hoppe ombord på OpenAIs nye funktion.
Konkurrencen om søgemaskiner og sprogmodeller er intens, og OpenAI har købt domænet chat.com, som fører direkte til ChatGPT. Målet kan være at skabe afhængighed af deres tjeneste ved at ophøje chat til et synonym for AI, ligesom vi bruger “Googler” som et begreb. Mange elever sætter lige nu lighedstegn mellem ChatGPT og AI, hvilket kan være en udfordring, vi skal adressere i undervisningen - AI er mere end chat.
I undervisningen lærer eleverne, hvordan de bedst foretager informationssøgning ved hjælp af søgestrategier og kildekritik. Det er dog langt fra perfekt, da det ikke er alle elever, der kommer til side 2 i deres søgninger, og hvis informationen ikke står i toppen af søgningen, antager de ofte, at den ikke findes. Samtidig påvirker reklamer søgeresultaterne, og AI er også begyndt at opsummere indholdet for brugeren.
Men er det virkelig løsningen at flytte søgefunktionen direkte ind i sprogmodellen? I dette indlæg vil jeg forsøge at uddybe nogle af de muligheder og udfordringer, jeg ser.
I den betalte udgave af ChatGPT har brugerne nu fået et lille ikon, hvor ChatGPT søger på nettet. Herunder kan du se en kort film, hvor OpenAI viser de nye muligheder.
I øjeblikket er funktionen kun tilgængelig for betalende brugere, men på sigt vil den blive rullet ud til alle brugere af ChatGPT.
Sprogmodellerne har fået meget kritik for, at de opfinder kilder, og når vi holder oplæg, har vi altid nogle slides i vores præsentation, der understreger dette. Her er der stor forskel på, om det er den gratis eller den betalte udgave af ChatGPT. Gratisudgaven hallucinerer i en sådan grad, at den er næsten ubrugelig, hvilket igen bidrager til ulighed mellem eleverne.
Da ChatGPT search kan finde informationer online, ligesom Microsoft Copilot og Google Gemini, åbner OpenAI principielt op for en dynamisk søgeoplevelse for brugeren. Dette kan hjælpe med at gøre søgninger mere præcise, hurtigere og give bedre resultater baseret på brugerens præferencer og tidligere søgninger. Hvis der er sider, vi ikke bryder os om, kan man opdatere sprogmodellens hukommelse, hvilket får dem til at forsvinde fra fremtidige søgninger.
Alt dette bidrager til at opbygge et ekkokammer, hvor vi konstant får præsenteret de oplysninger, som vi og sprogmodellen mener er korrekte, og hvor sprogmodellen ender med at forstærke brugerens mening. Vi mister måske noget af det ekstra, der følger med søgninger, såsom når vi finder nye, interessante kilder på side 4 i søgeresultaterne. AI i søgemaskiner og indbygget i sprogmodeller kan ende med at fungere som skyklapper, der forhindrer os i at se det store billede. Risikoen er samtidig, at vi bliver for afhængige af AI-systemer på en måde, der svækker vores egen kritiske tænkning.
Det store spørgsmål er dog, hvordan OpenAI håndterer kvaliteten og troværdigheden af de kilder, der præsenteres for brugeren. Vi er vant til, at det lige nu sker via forfinede algoritmer hos Google og Microsoft, som udvælger for os, og dem, der søgemaskineoptimerer, kommer oftest øverst i resultaterne. Lige nu er det ikke gennemsigtigt, hvordan resultaterne udvælges, men vi formoder, at det sker etisk. Her er det også markeret, hvad der er reklamer, og hvad der er reelle søgeresultater.
I mine egne tests af ChatGPT-søgning virker den dog ret fornuftig i valget af kilder, men jeg støder også på kilder, der er tvivlsomme. For eksempel AiPedia, Elblog.pl og Undetectable AI. Her er et eksempel, hvor ChatGPT-søgningen kommer med et korrekt svar, men kilden er AI-genereret på en tvivlsom side:

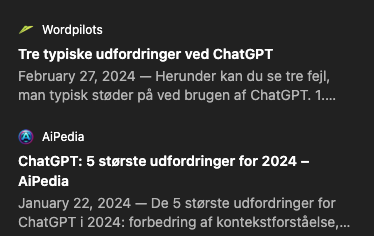
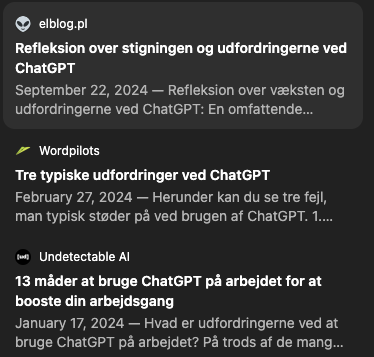
Eksempel på en række tvivlsomme kilder.
Generelt er det ofte uklart, hvordan kilder er blevet brugt, hvilket skaber en falsk tryghed ved søgninger. I dette tilfælde spurgte jeg ind til krav om løsøre i forbindelse med en bolighandel. Udfordringen er, at der tilføjes kilder, men alle kilderne er tests af robotplæneklippere – ingen af dem handler om det, jeg spørger om. Der kommer et svar, men kilderne bliver på ingen måde brugt, selvom det ser ud til, at ChatGPTs indhold stammer fra dem. Det er først efter flere forsøg, at jeg modtager kilder fra Skat og Minkøbermægler.dk.
Samtidig virker det, som om ordet “robotplæneklipper” vægter højere end “hus”, “krav” og “regler”, hvilket kan forklare svaret. Men det betyder også, at kilderne først bliver brugt korrekt, når vi spørger på en specifik måde.
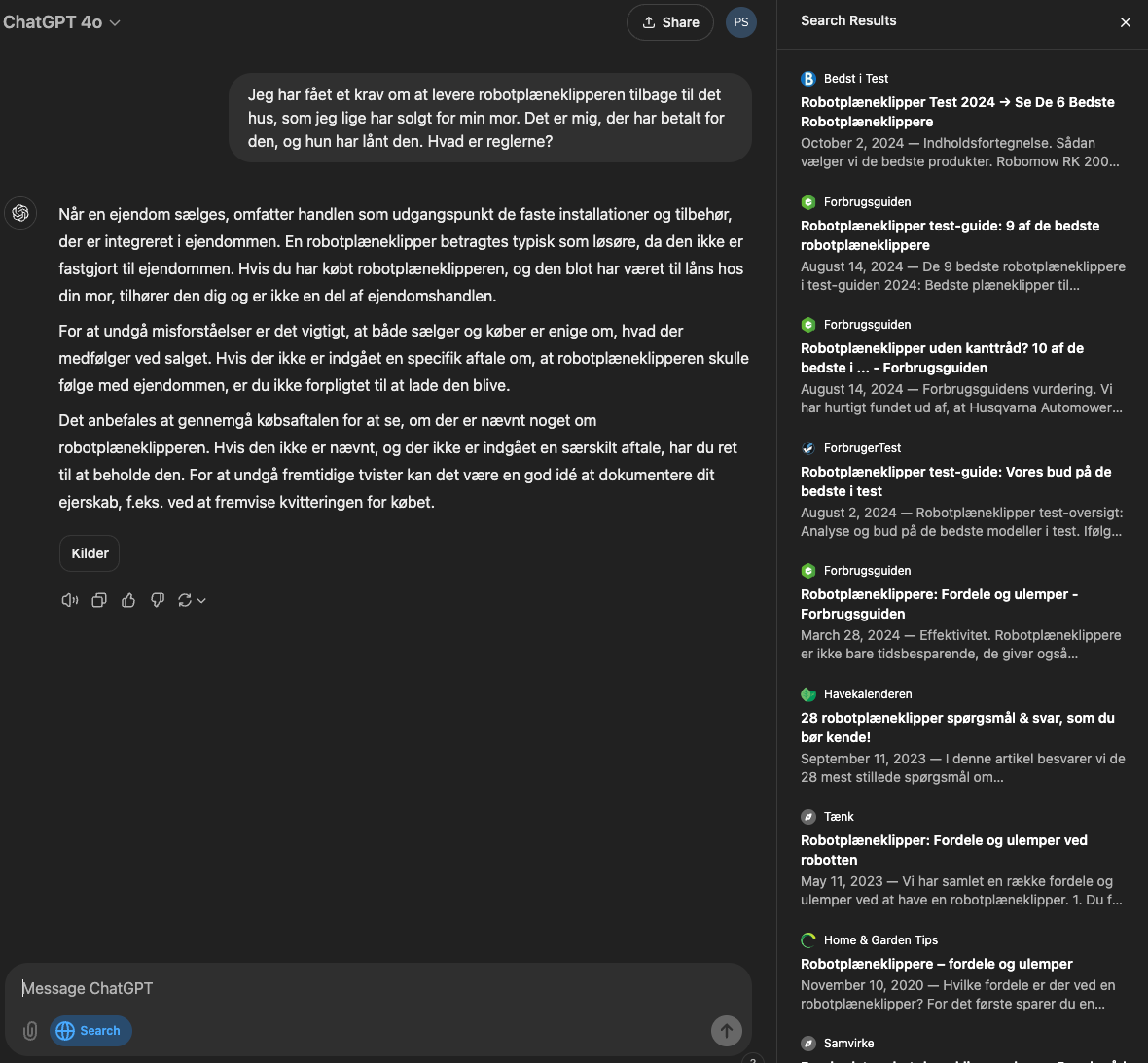
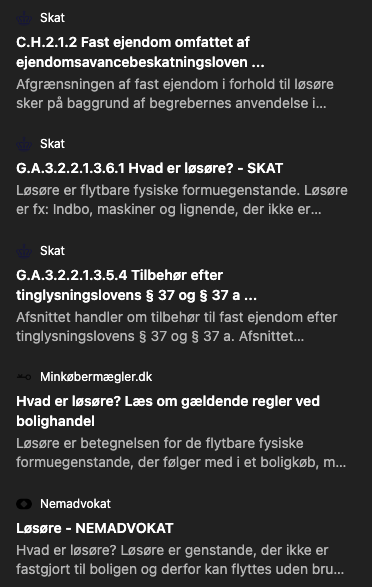
Men er det bedst, at lade afsenderen af en artikel eller en AI-model stå for opsummeringen og udvælgelsen? Begge tilgange har fordele og ulemper og indebærer risici for manipulation, fejl og mangler. I mine egne tests af ChatGPT search stødte jeg på mange tvivlsomme kilder, herunder små AI-genererede blogs, døde links, forældede oplysninger og indhold, der er gemt bag betalingsmure.
OpenAI samarbejder med etablerede kilder som Associated Press, Axel Springer, Condé Nast, Dotdash Meredith, Financial Times, GEDI, Hearst, Le Monde, News Corp, Prisa (El País), Reuters, The Atlantic, Time og Vox Media, hvilket kan indikere en positiv udvikling for informationskvaliteten. Samtidig er det muligt for websites at tillade, at OpenAI bruger indholdet, hvis man ønsker at bidrage til indholdet. Modsat kan man også blokere for AI.
Men det er stadig uklart, hvordan de håndterer emner, der ligger uden for disse vidensbaser, samt hvad der sker med materiale på andre sprog. I øjeblikket er der mange hjemmesider, der nægter sprogmodeller adgang til deres indhold, hvilket kan give en skævvridning af søgeresultaterne.
I modsætning til ChatGPT search er det svært at vurdere kilderne, eftersom de bliver gemt væk i baggrunden, men stadig bruges aktivt til at danne nye tekster. I modsætning til søgemaskiner, der viser en række resultater, som brugeren selv skal navigere i og vurdere, omskriver ChatGPT search resultaterne og præsenterer et sammenfattet svar med kildehenvisninger. Man behøver derfor ikke at gå ind på kilden, og der er ikke reklamer eller andet, som forstyrrer.
Dog mistes noget af incitamentet til at skrive på nettet – er ens side blot en fødekilde til sprogmodellerne? Især vil der måske være mange, som mister annonceindtægter og derfor vælger at blokere for sprogmodellerne. Det er kun de store, etablerede nyhedsmedier, der kan lave økonomiske aftaler med tech-virksomhederne, og dermed ender vi måske med at få et mere polariseret internet.
En anden væsentlig faktor er, hvordan brugeren formulerer sin forespørgsel. Selv små ændringer i formuleringen kan føre til vidt forskellige og til tider direkte forkerte svar fra ChatGPT Search. I en undervisningskontekst kan dette være problematisk, hvis eleven ikke har den nødvendige faglige viden til kritisk at vurdere modellens svar og heller ikke kan formulere en god forespørgsel. For eksempel, hvis en elev, der skal skrive en opgave om klimaforandringer, spørger ChatGPT “Hvad er årsagerne til global opvarmning?”, kan svaret være markant anderledes, end hvis der spørges “Hvilke menneskeskabte aktiviteter bidrager til drivhuseffekten?”. Det kræver en betydelig faglig viden at stille de rette spørgsmål til en sprogmodel og vurdere svarene. Hvis en elev ukritisk anvender disse svar i sine afleveringer, kan det føre til forkerte konklusioner og en lavere faglig kvalitet.
OpenAIs ChatGPT search er nok den vej, vi fremover skal søge efter information på nettet. Dog er der stadig mange ubesvarede spørgsmål om kvaliteten og troværdigheden af de kilder, som bliver præsenteret for brugeren. I undervisningen er det afgørende, at eleverne lærer at forholde sig kritisk til den information, de finder online – uanset om det er gennem traditionelle søgemaskiner eller AI-drevne værktøjer som ChatGPT Search. Vi må ikke lade os forblænde af den lette adgang til information og glemme at stille spørgsmål ved kildens troværdighed og relevans – faktisk bliver det hele endnu mere mudret, når AI nu blander søgeresultater sammen med træningsdata.
I skolen skal vi holde os opdateret på udviklingen inden for AI og søgemaskiner. Vi skal sikre, at vores elever har de nødvendige kompetencer til at navigere i en digital verden, hvor grænserne mellem søgning, opsummering og AI-generering bliver stadig mere flydende.