Fælles viden og videnskabsteori: udfordringer i en tid med generativ kunstig intelligens
I takt med at generativ kunstig intelligens, baseret på store sprogmodeller, som f.eks. ChatGPT, Gemini, Claude eller Copilot bliver en stadig mere integreret del af vores hverdag på uddannelsesinstitutionerne, udfordres vores traditionelle forståelse af viden og særligt begrebet "fælles viden".
Denne udvikling rejser fundamentale spørgsmål inden for videnskabsteori og tvinger os til at genoverveje, hvordan vi definerer, producerer og deler viden i vores samfund.
Inden jeg kommer til hvordan kunstig intelligens udfordrer vores fælles vidensgrundlag, og hvordan vi kan imødekomme udfordringen, er det nødvendigt at defineret hvad vi forstår ved viden, videnskab og fælles viden.
Hvad er viden og videnskab?
Videnskabsteorien, som disciplin, har længe beskæftiget sig med spørgsmål om, hvad viden er, hvordan den opnås, og hvordan vi kan sikre dens gyldighed. Samtidig har ontologien - læren om det værende og virkelighedens grundlæggende natur - spillet en afgørende rolle i vores forståelse af, hvad der eksisterer, og hvordan forskellige entiteter relaterer sig til hinanden. Disse to filosofiske grene er tæt forbundne, da vores opfattelse af virkeligheden (ontologi) påvirker, hvad vi betragter som gyldig viden (epistemologi). Siden oplysningstiden, måske endda siden Gutenberg trykte den første bog, har vi opbygget en tradition for at skabe og dele et fælles vidensgrundlag - en tradition, der har været afgørende for videnskabelige fremskridt og samfundets udvikling. Dette fælles vidensgrundlag har været baseret på Platons klassiske definition af viden som "sand, begrundet overbevisning", en definition der stadig er central i moderne epistemologi.
💡
Den danske ordbog definerer viden som: "Alt, hvad en person har lært om et eller flere emner, gennem erfaring eller undervisning."
Den store danske definerer videnskab på denne måde: ”Videnskab er en almen betegnelse for systematiske metoder til at frembringe, ordne og udbrede viden og kunnen samt resultaterne af denne aktivitet og de organisationsformer og administrative enheder (som fag og discipliner), hvorunder det foregår”.
Videnskab eraltså en systematisk metode, der bruges til fremskaffelsen, systematiseringen og udbredelse af viden, samt den viden, som er fremskaffet ved hjælp af en videnskabelig metode.
Disse definitioner understreger, at viden er noget, vi tilegner os gennem aktiv læring og erfaring.
Videnskab er mange ting. Søren Kjørup, som er professor i videnskabsteori, skriver, at videnskab er en:
"fællesbetegnelse for et utal af forskelligartede, delvis overlappende discipliner, der ud fra forskellige synspunkter kan samles (næppe nogen sinde helt konsekvent) i forskellige grupperinger."
Vi opdeler typisk i naturvidenskab, samfundsvidenskab, humaniora (den humanistiske videnskab), sundhedsvidenskab og teknisk videnskab, som alle har hver deres genstandsfelter, metoder og forklaringsmodeller.
Kombineres de to begreber videnskab og viden, fås videnskabelig viden. Videnskabelig viden er viden, der er baseret på videnskabelige undersøgelser og som kan efterprøves og begrundes gennem kilder eller ved hjælp af observationer og/eller eksperimenter.
Inden for videnskabelig forskning sikrer man høj kvalitet og troværdighed ved at offentliggøre sine resultater, f.eks. i videnskabelige tidsskrifter. Dette indebærer en kvalitetssikringsproces i form af peer review eller anden form for fagfællebedømmelse. Forskere deler deres resultater, så de kan gavne samfundet og andre forskere, der kan bygge videre på dem. Samtidig er forskere underlagt en række principper for god videnskabelig praksis, herunder lov om videnskabelig uredelighed, og deres troværdighed sikres af fælles normer for det videnskabelige arbejde.
Begrebet "fælles viden" refererer til denne kollektive forståelse og information, som deles af medlemmer af et samfund eller en faglig gruppe. Det er denne fælles viden, der muliggør effektiv kommunikation, samarbejde og fremskridt inden for videnskab og andre områder. Fænomenologien understreger dog, at al viden skabes i en social, kulturel og historisk kontekst, og at forskeren altid fortolker ud fra sin egen forforståelse. Hermeneutikken betoner ligeledes, at forskeren aldrig kan være helt neutral eller objektiv, og derfor altid bør synliggøre sine valg og italesætte sin forforståelse, som en del af afrapporteringen.
Videnskabsteorien skelner mellem forskellige former for viden og forskellige videnskabelige tilgange. Naturvidenskab, samfundsvidenskab og humaniora har hver deres særlige metoder og epistemologiske grundlag. Fælles for dem alle er dog idéen om, at videnskabelig viden skal være baseret på systematiske undersøgelser, der kan efterprøves og begrundes. Vi bør altid spørge os selv om følgende: Hvordan har vi fået den viden, vi har? Og hvad er det, vores viden er om? Et henholdsvis epistemologisk og ontologisk perspektiv på vores viden.
Hvordan udfordres vores fælles vidensgrundlag af kunstig intelligens?
Generativ kunstig intelligens kan medføre nye udfordringer, i forhold til vores forståelse af fælles viden og videnskabelige metoder. Når vi på traditionel vis søger informationer i artikler, bøger eller på internettet, er det os selv der udvælger kilder. Vi ved, i de fleste tilfælde, hvor kilderne kommer fra og kan derfor lettere validere troværdigheden og afsenderens intentioner. Søgning på internettet er underlagt algoritmernes magt, og vi får ikke nødvendigvis objektive svar, men svar som først og fremmest tilgodeser ukendte og uigennemsigtige algoritmers kriterier og ofte også annoncørers interesser, ligesom internettet oversvømmes af flere og flere falske historier og misinformationer. Vi kan dog, i de fleste tilfælde se hvem afsenderen er, og derfor forsøge at vurdere troværdigheden af kilden. Vi begynder dog at se brug af generativ kunstig intelligens ved skrivning af fagfællebedømte videnskabelige artikler - en kilde vi traditionelt anser som meget troværdig. Det kan udfordre vores tillid, og dermed gøre det endnu sværere at finde et troværdigt fælles vidensgrundlag.
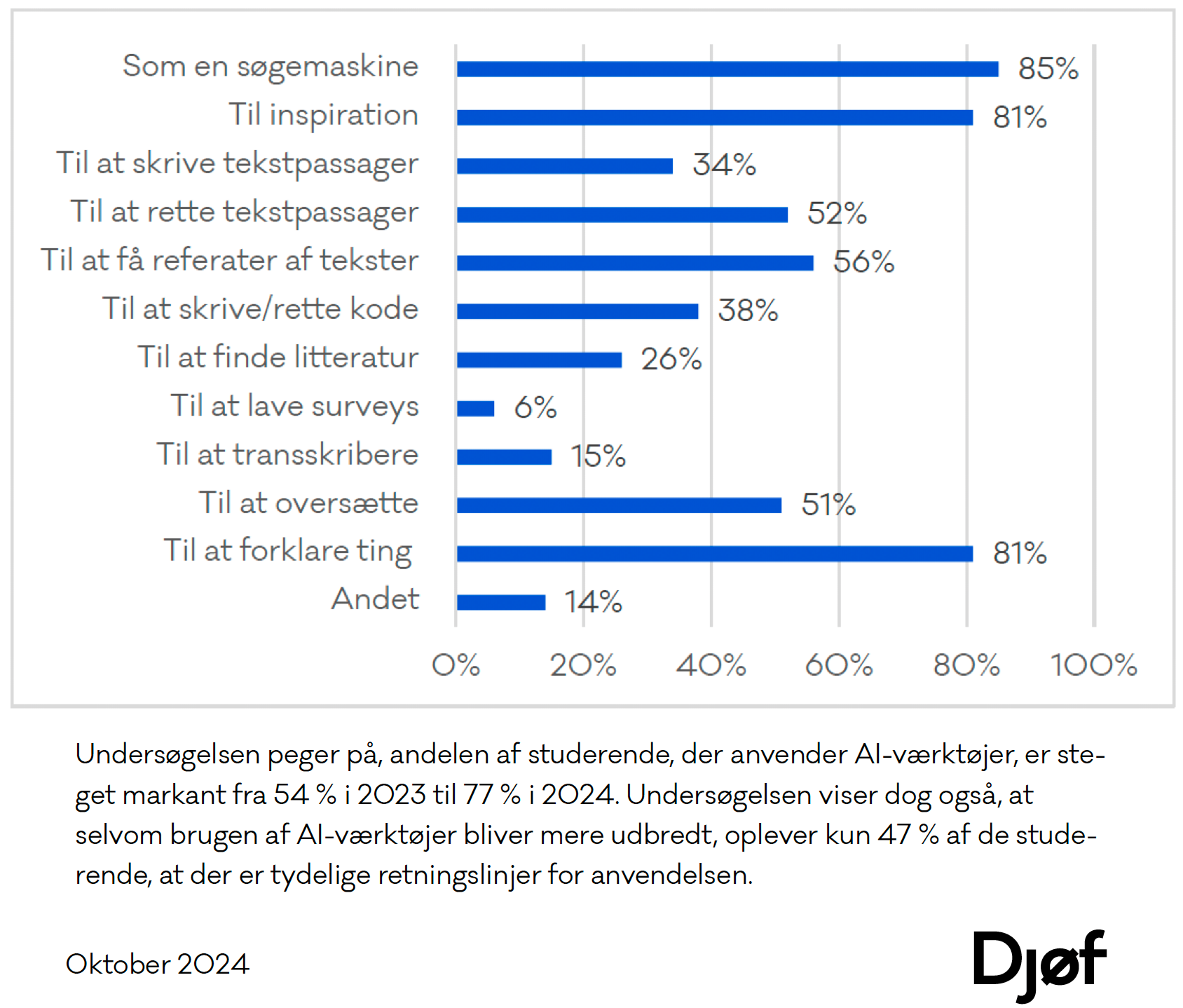
Generative kunstige intelligens systemer producerer information og foreslår løsninger, baseret på omfattende datasæt og sandsynligheder, uden en klar forklaring på, hvordan disse resultater er opnået. De største udfordringer ved dette er manglende referencer, mangelfulde data (der er ingen måde at vide, om et datasæt er fuldstændig repræsentativt), ikke-transparente datasæt og potentielt stor bias i datasættene - generativ kunstig intelligens er ikke bedre, end de data de er trænet på! Dette udfordrer vores traditionelle forståelse af, hvad der udgør valid viden og hvordan vi kan verificere den. Og helt galt går det, når internettets søgemaskiner indbygger generativ kunstig intelligens, som kan give sammenfatninger af søgninger og dermed også udvælger, hvad der er vigtigst i et søgeresultat. En undersøgelse lavet af DJØF blandt deres studerende viser, at 85% bruger ChatGPT som søgemaskine på studiet, og 23% også til eksamen!
Når søgefunktioner indbygges i sprogmodeller, som OpenAI gør i den nyeste version af ChatGPT, kaldet ChatGPT search, udfordres vores tilgang til kildekritik yderligere. OpenAI's alternativ til traditionelle søgemaskiner som Google og Bing leverer nemlig et koncentrat af søgeresultater med henvisning til, mere eller mindre troværdige, kilder. Dette rejser nye spørgsmål om, hvordan vi kritisk vurderer information. På viden.ai udforsker vi snart, hvilken betydning ChatGPT's søgefunktion kan få for undervisningssektoren.
En central videnskabsteoretisk udfordring i denne sammenhæng er spørgsmålet om epistemisk afhængighed. I takt med at vi i stigende grad benytter AI-systemer til informationssøgning og beslutningstagning, risikerer vi at blive afhængige af disse systemer på en måde, der underminerer vores egen evne til kritisk tænkning og selvstændig vidensproduktion. Vi er også underlagt automation bias, hvor vi som brugere nemt kommer til at stole for meget på de meget overbevisende svar, som systemerne giver, og confirmation bias, hvor systemets forslag nemt tillægges forskellig vægt, alt efter om det bekræfter eller strider mod ens egen forforståelse. Vi simplificerer komplekse problemstillinger og informationer (forenklingsbias) og går dermed glip af nuancer og detaljer.
Flere undervisere har fortalt mig, at elever har konfronteret dem og påstået, at det netop gennemgåede stof er forkert.
“ChatGPT siger noget andet, og det stoler jeg mere på”
I et tilfælde greb underviseren situationen og gik undersøgende til værks sammen med eleverne. Det viste sig, at svaret fra den kunstige intelligens var stærkt biased, og sandsynligvis stammede fra et andet verdenssyn afspejlet i de grundlæggende data.
Dette rejser spørgsmål om, hvordan vi kan opretholde en balance mellem at udnytte teknologiens muligheder og bevare vores kognitive autonomi.
Samtidig udfordrer kunstig intelligens evnen til at generere forskellige perspektiver på samme emne, idéen om en objektiv sandhed - et centralt koncept i mange videnskabsteoretiske traditioner. Dette kan føre til en form for epistemisk relativisme, hvor sandhed betragtes relativt til en bestemt referenceramme eller kontekst, som bl.a. bliver afhængig af f.eks. brugerens teknologiforståelse, faglige basisviden og evnen til at prompte den kunstige intelligens. Denne udvikling tvinger os til at genoverveje, hvordan vi kan opretholde idéen om fælles viden i en verden, hvor mange, potentielt modstridende perspektiver let kan genereres i f.eks. et undervisningsrum.
For uddannelsessystemet, der traditionelt har været baseret på formidling af en fælles viden gennem standardiserede pensum, fælles faglige mål og curricula, rejser denne udvikling særlige udfordringer. Hvordan sikrer vi, at elever og studerende udvikler en fælles vidensbase, når de har adgang til (og potentielt divergerende information fra kunstig intelligens? Dette spørgsmål er ikke blot pædagogisk, men dybt videnskabsteoretisk, da det berører kernen af, hvad vi forstår ved viden og hvordan den bør formidles.
Hvis hver elev modtager forskellige forklaringer - måske bare små nuanceforskelle - på det samme emne, risikerer vi at miste den fælles vidensbase, der er nødvendig for at skabe en sammenhængende og funktionel diskurs, både i skolen og i samfundet.
En af de mest fascinerende videnskabsteoretiske problemstillinger som kunstig intelligens rejser, er spørgsmålet om forholdet mellem viden og forståelse. Når kunstig intelligens kan generere meningsfuldt indhold uden egentlig forståelse, udfordrer det vores opfattelse af, hvad det vil sige at "vide" noget. Dette tvinger os til at genoverveje forholdet mellem information, viden og forståelse - centrale begreber i epistemologien.
Generativ kunstig intelligens, kan også ses som en epistemisk teknologi – et værktøj, der ikke blot behandler information, men også aktivt former, hvad der betragtes som viden. De er designet til at udlede mønstre og generere output, der efterligner menneskelig ræsonnering, uden gennemsigtighed omkring de underliggende processer. Denne uklarhed udfordrer traditionelle epistemologiske principper, som vægter forståelsen og verifikationen af de processer, hvorigennem viden produceres, højt.
Hvad kan vi gøre ved disse udfordringer?
For at imødegå disse udfordringer og bevare idéen om fælles viden, er det nødvendigt at styrke vores fokus på videnskabsteori og kritisk tænkning. Vi må udvikle nye metoder til at validere og integrere AI-genereret information i vores fælles vidensbase, samtidig med at vi fastholder de grundlæggende principper for videnskabelig metode og kritisk undersøgelse.
Dette kræver (måske) en ny tilgang til uddannelse og forskning, hvor fokus ikke blot er på at akkumulere information, men på at udvikle evnen til at evaluere, kontekstualisere og kritisk anvende information, uanset ophav. Det indebærer også en dybere forståelse af de epistemologiske og ontologiske antagelser, der ligger til grund for både vores traditionelle videnskabelige metoder og de nye AI-baserede tilgange til vidensproduktion.
Det udfordrer også vores traditionelle forståelse af, hvad der udgør valid viden, og hvordan vi kan verificere den. Samtidig rejser det ontologiske spørgsmål om, hvad der egentlig eksisterer i en verden, hvor kunstig intelligens kan skabe overbevisende “udgaver” af virkeligheden.
Kunstig intelligens giver os mulighed for at genbesøge og måske udvide centrale videnskabsteoretiske begreber som objektivitet, validitet og reliabilitet. Det tvinger os til at overveje, hvordan vi kan opretholde idéen om fælles viden i en verden, hvor information er let tilgængelig, men hvor kvaliteten og pålideligheden af denne information ofte er uklar.
I sidste ende handler det om at finde en balance mellem at udnytte potentialet i generativ kunstig intelligens og samtidig bevare og styrke de grundlæggende principper for videnskabelig metode og kritisk tænkning. Kun ved at gøre dette kan vi sikre, at vores fælles vidensgrundlag forbliver solidt og troværdigt. Denne udfordring er ikke kun relevant for akademikere og forskere, men for hele samfundet. I en verden, hvor information og dermed også mis-og disinformation spredes med lynets hast, er det afgørende, at vi alle udvikler en dybere forståelse for de tanker, der ligger bag videnskabsteori og epistemologi. Det er en udfordring, der kræver en fælles indsats fra uddannelsesinstitutioner, forskere og beslutningstagere.
Ved at tage denne udfordring seriøst og aktivt arbejde på at udvikle nye tilgange til viden og videnskabsteori, kan vi ikke blot imødegå truslerne fra generativ kunstig intelligens, men også udnytte dens potentiale til at berige vores fælles vidensgrundlag. Det kræver, at vi fortsætter med at stille kritiske spørgsmål, udfordre vores antagelser og aktivt engagere os i de epistemologiske og etiske debatter, som denne teknologiske revolution afføder. Det kræver også at vi er nysgerrige, og lærer om og med teknologien, så vi sammen kan finde de rigtige måder at bruge den på.
For at det kan lade sig gøre, er det nødvendigt med en opdatering af de mål, læreplaner og regler, som vores uddannelsessystem bygger på. Vi skal tilføje obligatoriske mål i læreplaner, som inddrager den nye teknologi som genstandsfelt, og vi skal tillade kritisk og reflekteret brug til eksamener og prøver, hvis ikke kunstig intelligens skal kortslutte vores uddannelsessystem og dermed udfordre vores fælles vidensgrundlag. Vi skal samtidig huske på vigtigheden af at have en solid grundfaglighed. Vi skal stadig lære uden teknologi, så vi opbygger et stærkt vidensfundament der gør, at vi kan fungere når teknologien ikke er til rådighed. Det er også vores grundfaglighed der gør, at vi kan udnytte teknologien korrekt, f.eks. prompte præcist og med den rigtige kontekst, og lige så vigtigt kan vurdere om de generative kunstige intelligensers meget overbevisende svar er korrekte. Kun ved at lære om og med teknologien, og også udprøve elever og studerendes viden om og anvendelse af teknologien, kan vi sikre at videnssamfundets fundament består.
I denne omstillingsproces må vi huske på, at idéen om fælles viden ikke blot er et akademisk koncept, men en grundsten i vores tillidsbaserede samfund. Det er gennem vores fælles forståelse og viden, at vi kan kommunikere meningsfuldt, samarbejde effektivt og træffe informerede beslutninger som samfund. At bevare og udvikle dette fælles vidensgrundlag i en tid med generativ kunstig intelligens, er derfor ikke blot en videnskabsteoretisk udfordring, men en samfundsmæssig nødvendighed.
Forskning og samfund - en grundbog i videnskabsteori, Søren Kjørup, Gyldendal Undervisning, 2003, (2. udgave)
Oh, P.S., Lee, GG. Confronting Imminent Challenges in Humane Epistemic Agency in Science Education: An Interview with ChatGPT. Sci & Educ (2024).
Innes, Judith E., & Booher, David E. (2018). Planning with complexity: An introduction to collaborative rationality for public policy (Second edition). Routledge, Taylor & Francis Group.
Scardamalia, M. (2002). Collective Cognitive Responsibility for the Advancement of Knowledge. In B. Smith (Ed.), Liberal Education in a Knowledge Society (pp. 67-98). Chicago, IL: Open Court.
Gillies, Donald. (2020). Artificial Intelligence and Philosophy of Science from 1990s to 2020.
Ward, Adrian F. (2021). People mistake the internet’s knowledge for their own. Proceedings of the National Academy of Sciences, 118(43).
Krause-Jensen, N. H., & Hansen, B. B. (2024). Hvad skal vi bruge videnskabsteori til? Om videnskabsteori på professionsuddannelser. Tidsskrift for Professionsstudier, 19(37), 96–107.