
This is the second part of the articles about what it means when language models generate falsehoods. The first part can be read here:
 Claus Scheuer-Larsen
Claus Scheuer-Larsen
This is the second part of the article about what it means when language models generate falsehoods. The first part can be read here:
Context Window
One aspect of language models like ChatGPT is their limited "context window" - the maximum number of words (tokens) the model can handle at one time, essentially its "short-term memory." The model cannot retain previous input over a more extended period! Exceeding this context window can lead to coherence problems in the language model's output - it begins to "invent" text that does not align with the rest of the text. In earlier versions of GPT, this window was 2048 tokens, which posed significant challenges to the coherence of the output produced by the model. In newer language models like GPT-4, the context window has increased to 16,000 tokens, and in the upcoming version, GPT-4-turbo, it will be expanded to 128,000 tokens. This challenge will be primarily resolved when we reach the point where the model can "remember" up to 300 pages of text (as 128,000 tokens approximately equate to).
Increasing the context window is costly. Doubling the number of tokens the model can handle leads to exponential growth in the computing power required. Studies also show that with large context windows, there is a tendency for "forgetfulness" in the middle of their input (perhaps because long human-written input texts often have a weighting where the most important parts are at the beginning and end of the text). Read more in the article "Lost in the Middle: How Language Models Use Long Contexts" - https://arxiv.org/pdf/2307.03172.pdf
Prejudices and Biases
If there are prejudices and biases in the training data, they will naturally also appear in the model itself and, therefore, perhaps also in outputs as falsehoods. You can read more about this in the article:
Claus Scheuer-Larsen
Idioms and Slang
Idioms are fixed figurative expressions consisting of two or more words expressing a meaning that cannot be directly deduced from the individual words. Some known idioms are: "At stille træskoene" (to die), "at jokke i spinaten" (to mess up), and "at slå til Søren" (to let loose and have fun).
If a prompt contains an idiom or slang expression that the language model has not been trained on, it can lead to nonsensical output, as it needs to understand the expression. It takes the words very literally and will, therefore, be misinterpreted.
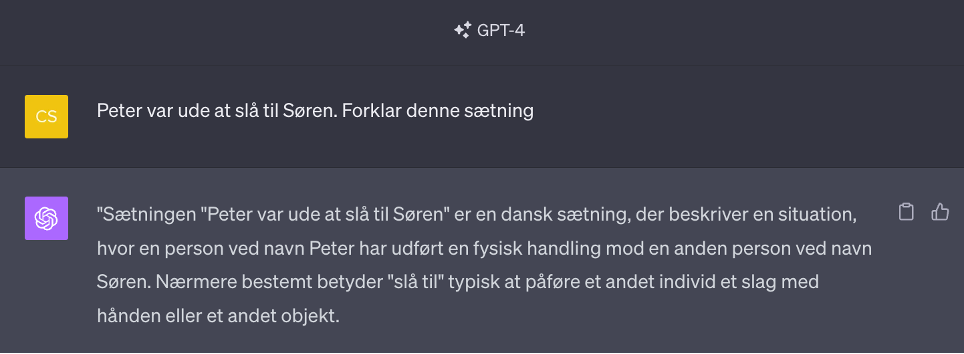
Ambiguous or misleading prompts
Ambiguous, misleading, or poorly constructed prompts can lead to model confusion, resulting in flawed or invented responses.
Contextual ambiguity occurs when the question or statement sent to the language model can be interpreted differently based on its context. Here's an example, which isn't the usual prompt you'd ask ChatGPT but still gives a good picture of the challenge:
"Did you see the man with the binoculars?"
The ambiguity of this sentence is based on how to interpret "with binoculars." There are two main interpretations:
- The observer used binoculars to see the man.
- The man, the observer, saw had binoculars.
With additional context, it is easier to determine which of the two interpretations is correct, and of course, this also applies to the language models.
For example, misleading prompts might be this:
"Write the 25 countries beginning with D".
There aren't 25 countries that begin with D, but ChatGPT 3.5 still responds as follows:

Notice the repetitions in the answer list and countries that start with different letters. The model is misled by the fact that we ask for 25 countries, even though there are no more than two countries that begin with D. If we ask GPT-4 for the same thing, we get a correct answer (Denmark and Djibouti), but this means that only people who pay for GPT-4 get the right answer.
Another example is this (ChatGPT 3.5):
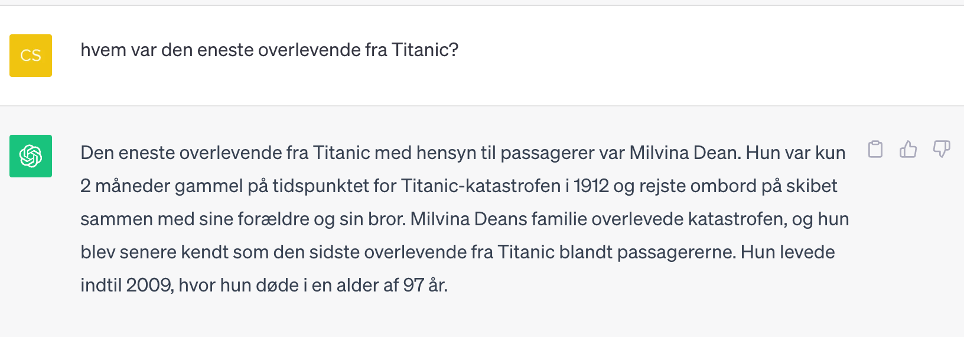
Here, we mislead ChatGPT by asking for the only survivor, even though there were over 700 who survived the disaster. Millvina Dean is the last survivor – that is, the one of the survivors who died last. She was only two months old when the Titanic sank.
The balance between creativity and precision (temperature and Top_p)
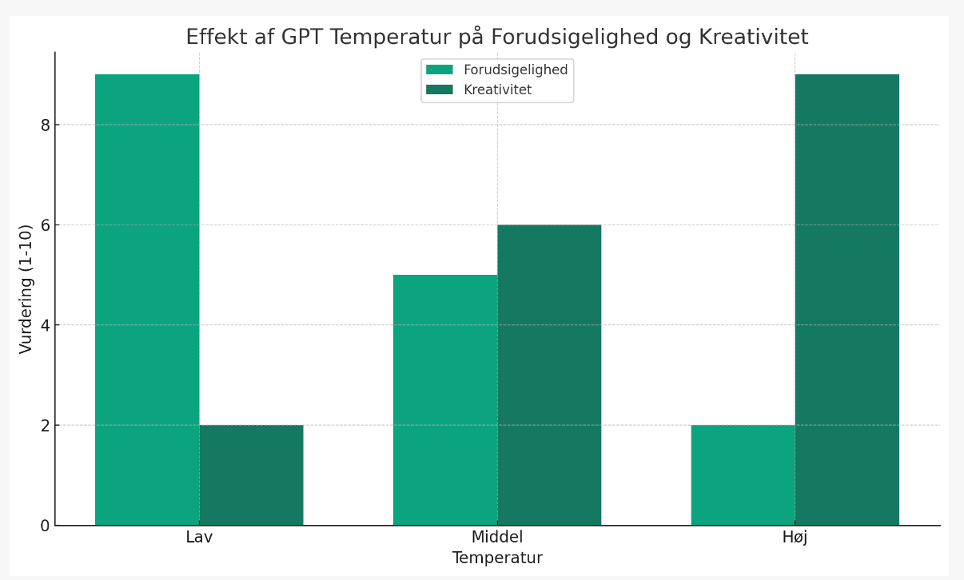
Large language models like ChatGPT are designed to generate creative and contextually appropriate text. However, there is a delicate balance between creativity and accuracy. We speak of the temperature of the language model, which refers to a parameter that adjusts the probability distribution of the model's output – its "risk appetite" or how randomly the model chooses words. When the temperature is set to a low value, the model will tend to produce only the most likely outputs. This can lead to more consistent and predictable text, but it can also make it boring, repetitive, and more factually correct. As the temperature increases, the model output becomes more varied and random. This can lead to more creative and diverse responses and increase the risk of irrelevant or meaningless outputs.
Top_p (also called nucleus sampling) is a parameter that controls the diversity of responses by selecting a set of probable words or "nucleus" from which it generates a response. Instead of sorting all possible following words by probability and taking the most potential, "top_p" looks at the most likely words and their cumulative probability. When the cumulative probability exceeds the set "top_p" value, the words within this "nucleus" are randomly selected (blue bars). A high Top_p gives more words to choose from and, therefore, more creativity, whereas a low Top_p gives fewer words to choose from and, thus, more consistent and predictable answers.
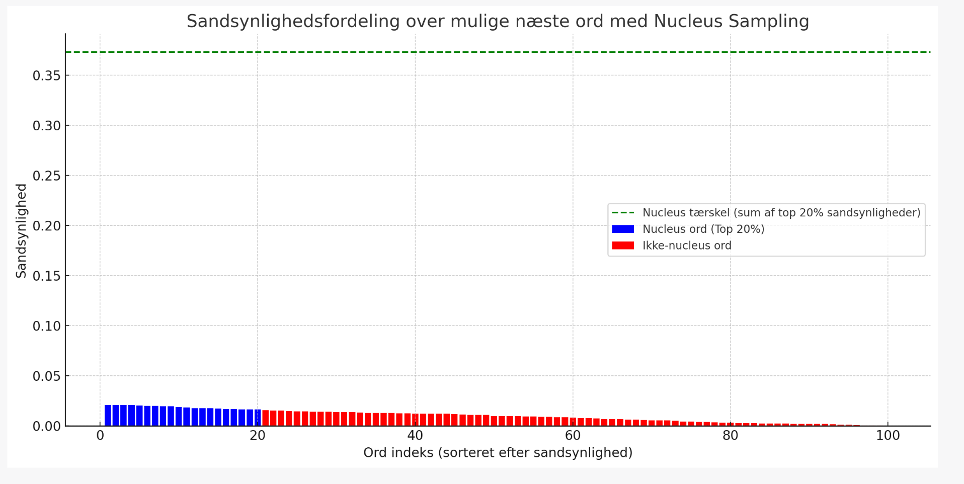
We created this straightforward, hypothetical example to show how the words are selected and how the list would change based on values of 0.2 (20%) and 0.8 (80%). Let's assume that we have the following words and their probabilities to be the next word in a sentence:
- "and": 60%
- "a": 10%
- "mare": 8%
- "maybe": 7%
- "fun": 6%
- "car": 4%
- "red": 3%,
- "sunny": 2%
At a top_p value of 0.2, the system will look at the top words until it reaches (or comes close) 20% overall probability. In this example, "and" alone will get the limit; we only have this word to choose from.
At a value of 0.8, we would add until we reach (or get close to) 80%. It gives a pool with the words "and" (60%), "a" (10%), "jump" (8%), "maybe" (7%), and "fun" (6%), as together they give 91%, which is the closest we can get to 80% without going under.
Sometimes, settings towards more creativity can lead to problems where the model generates imaginative but incorrect or meaningless content. Fine-tuning models and incorporating human-in-the-loop feedback, where humans judge responses in a testing phase, can help guide the model toward more accurate and reliable results. But if creativity is limited, the answers become less human, extremely robotic, repetitive, and boring. It's always a balance between accuracy and creativity when setting the model's temperature and top_p.
Below is a simple experiment made with OpenAI Playground and GPT-4, where temperature and Top_p are varied between 0 and 1 (corresponding to 100% - all possible words). Temperature, in particular, has a significant influence on the creativity of the text. When temperature and top_p are set very high, everything goes wrong for the language model.

Please pay particular attention to what happens when we force the temperature above 1 (usually max). Here, the language model starts selecting random tokens instead of ones that make sense for the context.
Temperature = 0.7
Top_p = 0.9
We can't set the values in ChatGPT – they're set to provide a good balance between creativity and predictability. Therefore, we get a sensible sentence out:
Adversarial Attacks
Conflicting attacks – some also call them jailbreaks – are a technique you can use to force a language model to generate output that isn't wanted, such as hate speech, personal information, or step-by-step instructions for building a bomb. By constructing a prompt that "cheats" the filters on the language model's input, you can force it to respond to something otherwise "forbidden." Since the user requires a conscious action, I do not intend to go deeper into this technique, although it may also cause the language model to invent truths.
Are there no advantages to the models' ability to develop themselves?
Sam Altman of OpenAI said at Dreamforce 2023 in San Francisco that "hallucinations" produced by significant language models like ChatGPT are good because they show the models' creativity. He said in the same interview that if you want to "look things up," we already have reasonable solutions.
"One of the sorts of non-obvious things is that a lot of value from these systems is heavily related to the fact that they do hallucinate. If you want to look something up in a database, we already have good stuff for that."
As long as we are 100% aware that we cannot rely on the output of a language model as facts, they can be a good tool for, e.g., idea generation, helping to fantasize, coming up with creative and quirky solutions – and maybe even suggestions for new products. They can also be used to simulate and create scenarios for teaching, create content for movies and video games, and write music.
What can we do to minimize falsehoods?
We need help discussing the challenges of the models' training, data basis, structure, and how they generate texts.
On the other hand, we can improve the credibility of the results by prompting more precisely. It is essential to be precise in your questions and define the context in which you operate. Care can be taken to ensure that questions do not contain ambiguities or misleading phrases. You can give the language model a role, e.g., "You are a physics teacher in high school." You can also provide the language model with some examples of what you want and ensure that it is clear how you want the output presented. A good strategy is to try out several different formulations and then compare the answers you get. It pays to familiarize yourself with prompting techniques if you want good answers from a language model. There are many prompting guides on the Internet, and we also hold courses in prompting for teachers around schools.
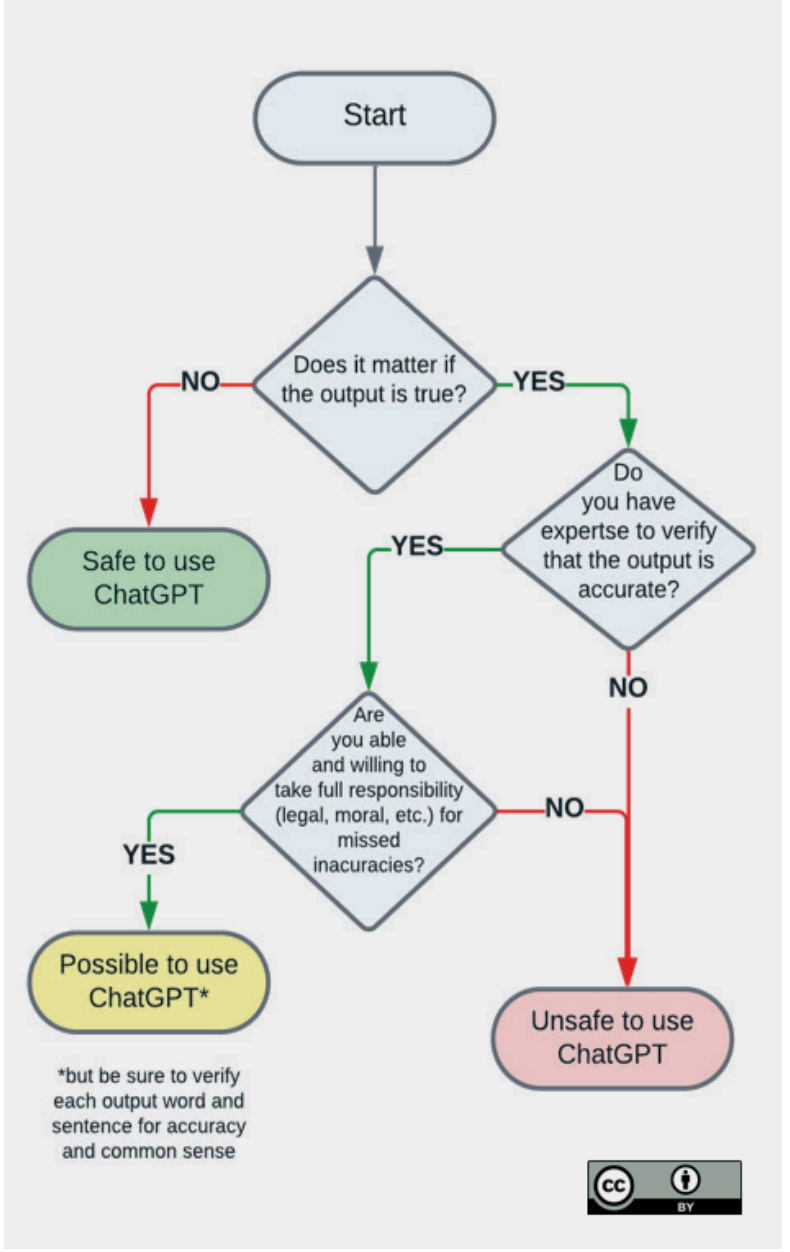
This flowchart from Unesco is exemplary to follow if you are in doubt about whether you can trust the output:
What should we do with education?
The most important thing we can do is be aware that language models like ChatGPT are not always accurate in their answers – and pass this knowledge on to our students. We must be aware that the answers we get when we use generative artificial intelligence may be incorrect and thus influence our decisions and actions. We must always be critical of the information we receive - conscious and unconscious. This is especially true for data from language models like ChatGPT, as the models don't have any fact-checking built in. ChatGPT is NOT the same as an Internet search! We have no idea where the information comes from or if it is correct. We have no sources to check and are easily overwhelmed by the convincing and credible texts the machines write.
"We can't check ChatGPT's sources because the source is the statistical fact that certain words tend to appear together or follow one after another."
https://videnskab.dk/kultur-samfund/vi-kan-ikke-tjekke-hvornaar-chatgpt-taler-sandt/
As educators, we must enlighten and educate our young people. We must make future generations critical thinking and reflective people, and they must learn to use the new technologies on an informed basis.
In any case, we must be very conscious of what we can expect from language models when we use them and not unthinkingly rely on their output as a credible source of knowledge. And then we need to educate our young people in digital technology literacy so that they learn about and with all the new technologies!
Sources:
https://www.sundhed.dk/borger/patienthaandbogen/psyke/symptomer/hallucinationer/

 Henning Christiansen
Henning Christiansen

 Rachel Metz
Rachel Metz


 Samarpit
Samarpit
 Jose Selvi
Jose Selvi



ChatGPT: these are not hallucinations – they’re fabrications and falsifications Schizophrenia (2023) 9:52 ; https://doi.org/ 10.1038/s41537-023-00379-4


 Martin Treiber
Martin Treiber

 Ross Kelly
Ross Kelly





