
In the context of large language models such as ChatGPT, one often encounters the concept of hallucinations - one speaks of the model as "hallucinating." Just as I wrote in the article about biases in language models, which are most often referred to as bias (https://viden.ai/en/a-nuanced-view-of-bias-in-language-models/), here again, we have a concept that is imprecise and means something else. Some have suggested the idea of confabulation as a substitute for hallucination, but it's not much better.
Here, we see an example of anthropomorphism—attributing human attributes, feelings, or intentions to non-human entities. Anthropomorphism derives from the Greek words "anthropos" (human) and "morphē" (form). When we use phrases such as artificial intelligence, machine learning, the language model understands or thinks, the model's memory and that it hallucinates or confabulates, we attribute human-like features to the machines – just as we often see artificial intelligence depicted as a humanoid robot. Read also the article: https://viden.ai/en/ethical-aspects-of-chatbots-in-education-the-uncanny-valley-of-the-mind/

Hallucination, confabulation, and other anthropomorphic metaphors
In a medical sense, hallucination is a sensory experience without an external influence on the sensory organ. For example, you may hear and see things that do not exist or are unreal but that you perceive as accurate. Hallucinations can occur from mental disorders such as psychoses and schizophrenia, from changes in the brain, or after taking drugs such as LSD. Hallucinations must be sensory impressions that require consciousness – something language models do not have!
Confabulation means that a person unconsciously "poets" what they cannot remember and fills gaps in their memory with fantasy experiences that they mistakenly believe to be true. The person will be able to answer questions quickly and in detail—but incorrectly—that require recalling information from memory. These fabricated memories are not created deliberately to mislead or lie but arise in certain brain diseases, such as dementia disorders or brain trauma, where memory is affected. Confabulation is related to imagination, perception, and belief – something that only human beings, not language models, possess.
Both of these concepts are thus related to the human brain and its associated phenomena, such as sensory impressions, perception of reality, consciousness, imagination, and belief. Using these concepts as metaphors for the errors of language models can be problematic, as it can reinforce anthropomorphic notions and make machines more human.
But then, what should we call it when ChatGPT writes something untrue or doesn't make sense, and how does it even come about? Some call it "bullshitting", others say that the language model lies (again, a word referring to a - conscious - human act).
There are several suggestions for non-anthropomorphic concepts, including "algorithmic junk," "tendency to invent facts," "logical errors of models," and "fabricated or invented information," including these coming from the two articles below. However, it is debatable whether the word "invent" is anthropomorphic.
- "A tendency to invent facts in moments of uncertainty"
- "A model's logical mistakes"
- Fabricating information entirely but behaving as if spouting facts
- "Making up information"

/cdn.vox-cdn.com/uploads/chorus_asset/file/24413225/Bard_Padding.png)
When we use words that we usually associate with something human to describe artificial intelligence, it is partly due to the lack of better concepts. We do not yet have a language to explain artificial intelligence, so we choose something we can relate to. Of course, this has the advantage that most people can understand what they mean to some extent, but it can also be dangerous and help humanize the technologies to an unfortunate degree.
In this case, I don't have a better guess than that the language model can sometimes generate factually incorrect, incoherent, irrelevant, repeating, or unexpected outputs. On the other hand, I will uncover some types of inconveniences seen in large language models and explain how these inconveniences can occur. This article does not cover all the challenges, but it presents the most important ones and should provide a good background for understanding the challenges and their possible implications.
If you read the small print below the input field in ChatGPT, it says the following:
"ChatGPT may produce inaccurate information about people, places, or facts."

OpenAI also writes the following on its website:
"These models were trained on vast amounts of data from the internet written by humans, including conversations, so the responses it provides may sound human-like. It is important to keep in mind that this is a direct result of the system's design (i.e. maximizing the similarity between outputs and the dataset the models were trained on) and that such outputs may be inaccurate, untruthful, and otherwise misleading at times."
What inconveniences may arise, and how do they appear?
To fully understand why inconveniences such as erroneous answers and falsehoods can occur in large language models like ChatGPT, it's important to remember that models are probabilistic predictive models. These models predict words based on statistics and are trained on large data sets of texts. During the training phase, ChatGPT is exposed to vast amounts of text, which it uses to learn patterns and connections between words. It is important to note that the model needs an understanding of the world or the concepts it encounters. It simply knows to generate text based on the patterns it has observed in training data. When language models write falsehoods, it is a product of them trying to "fill in the gaps" in their statistical models by "creating" content that meets the needs of questioners. In the following, I will look at why there may be gaps in the models and how the models, therefore, create inappropriate texts. Models are constantly improving, but even the best language models sometimes make mistakes.
Lack of understanding of reality
Language models need an understanding or awareness of the world. They mimic patterns from the data they were trained on to generate reasonable and convincing answers. Still, sometimes, they are meaningless, inaccurate, or fabricated – at least in terms of facts.
Insufficient or faulty training data
Suppose the data the model is trained is not representative of the natural world (e.g., bias or bias) or contains errors (e.g., misinformation). In that case, the model can learn erroneous patterns.
If the model becomes very large, as the latest GPT models are, there is a risk of a phenomenon called the "Curse of Dimensionality". The size of the training dataset must grow exponentially with the number of dimensions (features/parameters) in the model to obtain an adequate and accurate model. In other words, the more dimensions data has, the harder it becomes to train an exact model because the space of possible solutions becomes larger. This can lead to a "dilution" of data in the model, which makes it difficult to find correlations and patterns in the data if there is insufficient training data. The model can thus become so complex that it becomes less accurate, coherent, or contextually relevant.
Another essential thing to remember is that language models like ChatGPT are "pre-trained," i.e., they are trained once and for all and are not re-trained. ChatGPT completed training in September 2022 (GPT-4 also has training data from 2023) and, therefore, does not know anything that has happened after that date. The models also do not have any mechanisms to validate the correctness of the answers they give us.
Knowledge gaps
When talking about "knowledge gaps" in training language models like ChatGPT, it is about the fact that there may be areas where the model either lacks accurate information or has conflicting or inaccurate data. These shortcomings can lead to the model generating information that must be corrected or based on erroneous assumptions. If you prompt on a particular topic, knowledge about that topic may not be included in training data, so the model will likely make a "guess", resulting in imprecise or incorrect answers. Suppose there are several possible angles on a topic in training data (divergences in source data) or incorrect descriptions (misinformation). In that case, the model will also risk answering incorrectly or angled in an unfortunate direction. Keep in mind that a massive part of training data comes from the Internet and part from non-validated sources. To solve the need for more knowledge, methods are being researched where synthetic data is generated to supplement the training set with gaps. One can also exploit external sources of knowledge, such as search databases on the Internet. This option has ChatGPT version 4 (paid edition), as it can access the Internet with Bing Search. By integrating external data into language models, their ability to give accurate and informative answers and say they know nothing about the subject can be improved.
Overfitting (overfitting) of models
Overadaptation occurs when a model becomes too complex and begins to memorize the training data instead of learning the underlying patterns. This means the model performs exceptionally well on training data but gets into trouble when presented with new unknown data. The problem arises because the model gets so much detail that it must generalize its knowledge to different contexts. This means that the model becomes too specialized to generate text similar to training data at the expense of the ability to generalize to new, unseen inputs. This overfitting can result in the model generating plausible-sounding text but factually incorrect or unrelated to the input. The figure below shows different ways to adapt a model to a dataset consisting of points. With both the under-adapted and the over-adapted model, the model will need help interpreting a new data point we introduce.
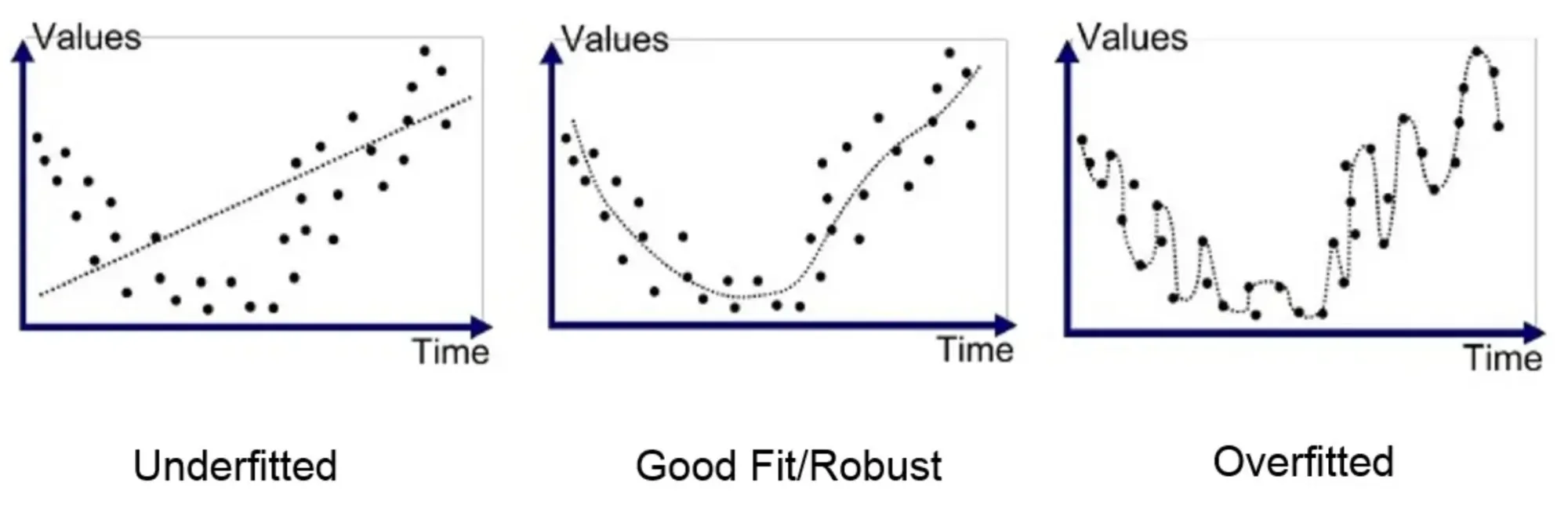
Imagine a language model tasked with generating movie reviews. The model is trained on many movie reviews. As the training progresses, the model will inadvertently start building specific phrases, genre traits, or plot details from the training data into its statistical model – it over-adapts its model. While this can result in persuasive reviews that mimic the style of the training data if presented with plots and genres it has met during training, in turn, it will have significant problems (and perhaps begin to mention traits of the genres and plots it knows from training) when faced with new genres or movie plots it has not encountered during training.
A more straightforward example is the following: Imagine that we train a language model on many texts about apples. Most texts contain that apples are red, and the model will over adapt to this knowledge during his training. If we ask the model about the possible colors of apples, the model might answer that all apples are red – even though we know that apples can easily be yellow and green, too. The model answers are untrue due to an overadaptation of data during training.
Overfitting can occur if data has high variance and low bias or if the model needs to be more complex in its design and at the same time has too little training dataset.
Underfitting (underfitting) of models
Different from overadaptation, there is also underadaptation, where the model becomes far too simple to capture the complexity of training data. Suppose we train a language model on many texts about apples, their varieties, colors, origin, cultivation methods, usage, etc., and the model being formed is under-adapted. In that case, it will not capture all the details from training data. If you ask the model about apples, it might answer very generically that apples are a fruit. This is not directly wrong, but it is unnuanced and without detail.
Similarly, a movie review from a custom model will be coherent, superficial, and with little info about the film's plot and genre. Underadaptation can occur if there is high bias and low variance in training data or if the model needs to be more complex and training data is too sparse (and perhaps too noisy).
Underfitting is relatively easy to detect by testing. It is, therefore, not seen in large language models. In contrast, overfitting can be much harder to detect, as the model can come up with compelling and detailed answers that are untrue.
In the second part of the article, published next week, we will look at a few more reasons for possible inconveniences and how they can be avoided. We also discuss their importance when using language models in education and what we need to know.
Sources:
https://www.sundhed.dk/borger/patienthaandbogen/psyke/symptomer/hallucinationer/

 Henning Christiansen
Henning Christiansen

 Rachel Metz
Rachel Metz


 Samarpit
Samarpit
 Jose Selvi
Jose Selvi



ChatGPT: these are not hallucinations – they’re fabrications and falsifications Schizophrenia (2023) 9:52 ; https://doi.org/ 10.1038/s41537-023-00379-4


 Martin Treiber
Martin Treiber

 Ross Kelly
Ross Kelly





