
In this article, I will look at what happens to all the entries we make, for example, ChatGPT, Google Bard, or Microsoft Bing, and why we might need to be careful about using them in teaching. Sometimes, we forget that artificial intelligence did not emerge with education in mind but is more of a product controlled by big tech companies to make profits. For example, OpenAI has gone from being an open-source company that wanted to make the technology open and accessible to everyone. But gradually it has developed into a very closed company that will not tell about changes in its latest model.
It is important to understand that GPT is a pre-trained model that builds on an existing body of data and does not continue to evolve or learn after it has been implemented. This means that the answers we get from GPT are based on the knowledge gained through prior training and not on continuous adaptation or learning.
Looking ahead and thinking about the next generations of artificial intelligence, it is interesting to consider how these models can potentially use behavioral data for further training and improvement. In this article, I'll dive into how future models might be able to collect and leverage users' behavioral data to improve their performance and become even more human in their communication.
Also read the articles:
- Focus on privacy
- Focus on closed knowledge databases
- Transition to automation ethics
The helping hand of surveillance capitalism: the chatbot
The great challenge that language models struggle with is credibility in what is written, and at the same time, they must also be as human as possible. To achieve both knowledge and credible output, language models must package the raw data in a communication that appeals to people. Currently, we see the wrapping as the chat feature of ChatGPT, but soon, Siri, Alexa, and Cortana will surely be enriched with artificial intelligence. Thus, we will be able to converse with the language models just as naturally as when talking to a person. But how can you make a chatbot that seems human? The answer is simple: collect users' behavioral data and train artificial intelligence using this data.
Collection of behavioral data as payment
Shoshana Zuboff explains in her book, The Age of Surveillance Capitalism, that the ethics of the digital age can be compared to behaviorist Burrhus Frederic Skinner's so-called Skinnerboks. The rail box is a tool for studying the behavior of animals over time, where the animal is isolated from the environment. In the box, the animal is affected by positive and negative stimuli, such as electric shocks, food, heat, sounds, smells, etc. When a reward accompanies a behavior, the likelihood of it occurring again increases. If, in turn, the behavior is accompanied by a punishment, it will be less likely that this behavior will occur in the future. Using the experiments with Skinner's box, the psychologists believed that it was possible to learn more about how the animal would react to influences in the real world.
We can compare Skinner's box with the chatbots and the training that people are currently doing without any transparency or any kind of regulation.
When we write together with the artificial intelligence in a chat window, we reveal our behavior to the companies behind it, just as the laboratory animal does to the researcher in Skinnerboksen. If we get a text that makes sense, we might give it a like. If we are unsatisfied with a text or an answer, we ask the artificial intelligence to clarify its answer. Every interaction with the chatbot mirrors human communication and sets a precedent for the chatbot's future behavior.
The researchers call this method Reinforcement Learning with Human Feedback (RLHF), and through it, the models are trained to come up with answers that the recipient finds satisfactory. In this training, the model receives rewards for responses in the same way as training a dog with treats. If the model receives an illegal query or provides an illegal response, these will be flagged using human feedback. Thus, the model is trained to filter these and "learns" both the good and bad answers, but also the answer that violates the company's guidelines.
Artificial intelligence becomes a shadow of human understanding
There can also be implied communication between people in not saying anything. For example, a short no can mean yes or maybe, and the comment "You big idiot" can be positive. But once we have seen what the artificial intelligence has written of texts, we do not need much imagination to imagine that it will become even better at answering/speaking like a human. We won't be able to tell the difference at some point because artificial intelligence behaves like a human, and then we have to worry first. For example, when we send a text to the chatbot, there is an answer that sometimes makes sense, but other times is slightly or completely wrong. Here, we are already providing valuable information to artificial intelligence while training new ways to communicate with artificial intelligence.
However, we must always consider that humans have a physical experience of our world and that the perceived context has many more touchpoints than artificial intelligence. Humans process the world through all their senses to such an extent that artificial intelligence cannot keep up. And current artificial intelligence has no concept of the physical world. It acts on mathematical models and statistics for the next word, sign, or phrase (tokens) and guesses what we want to hear.
Now, I am actually where I want to go with the above text because while we write or talk to artificial intelligence in teaching, our way of communicating to and with it is collected. The human behavior is collected, processed, and subsequently used to make the models more human. Now, it is not only important data points from the collected databases but also our very forms of communication and human response patterns that are mapped and replicated.
People do not always act rationally, as when, for example, we repeatedly try to get the chatbot to answer something that we know is impossible based on the guidelines. But we do it anyway, and why? That's because we're curious, boundary-seeking, and built to make mistakes.
Do we let the model capture our students' communication?
If we try to transfer the above to our teaching, we begin to reinforce the training of the models. Students have a different language than adults; e.g., they often don't use periods at the end of text messages, insert emojis, or replace words with highly implied slang. They most likely do not comply with the rules of orthography, and in this way, they are developing and influencing our written language. This influence has always occurred as a natural evolution in our language. Still, language models have difficulty picking up these changes because they are trained for a different type of text. The above input is, therefore, valuable to the language models because they can have a proboscis directly down in the current language development. It's not just texts from Wikipedia or Reddit but live queries that can give the model more human qualities and mimic an entire generation's communication. Among other things, when we ask the model to change the target group in its response, it will be able to understand how to write to a 14-year-old student while at the same time wrapping the text in the language of communication of youth culture.
But here, another challenge arises because the model will thus begin to affect the students' communication patterns based on what it has previously received of input and can thus act as self-reinforcing in a direction that we may not want. It may help reinforce prejudices or stereotypes and thus affect all parts of our communication. We must constantly consider that it is American tech companies that control this entire development for profit. Right now, it's about coming up with the best language model and collecting data/behavioral data to train the next one.
We therefore need to have an open discussion about all these ethical issues, because otherwise it is the tech companies that steer the train without any regulation in speed or direction.
Questions for the ethical discussion:
- Is it ethical to use chatbots in education when they are developed and controlled for profit by big tech companies?
- How do we ensure that we know whether it is a human or an artificial intelligence we are talking to - and is it important to know?
- Should there be more transparency and regulation in artificial intelligence training to protect user privacy and security?
- Should we be concerned about how AI affects students' written language and communication patterns?
- How can we ensure that AI does not reinforce existing prejudices and stereotypes in communication and behavior?
- Is it ethical to use chatbots in education when they can influence and change an entire generation's communication?
- How can we ensure that new technology does not undermine students' ability to think critically and explore their ideas and attitudes?
Sources


 Soroush_Saghaf
Soroush_Saghaf
 Technology
Technology




 Paul Lewis
Paul Lewis
 Af Sabrine Mønsted
Af Sabrine Mønsted
 Garling Wu
Garling Wu
 Chloe Xiang
Chloe Xiang


 Will Douglas Heaven
Will Douglas Heaven

 Contributors to Wikimedia projects
Contributors to Wikimedia projects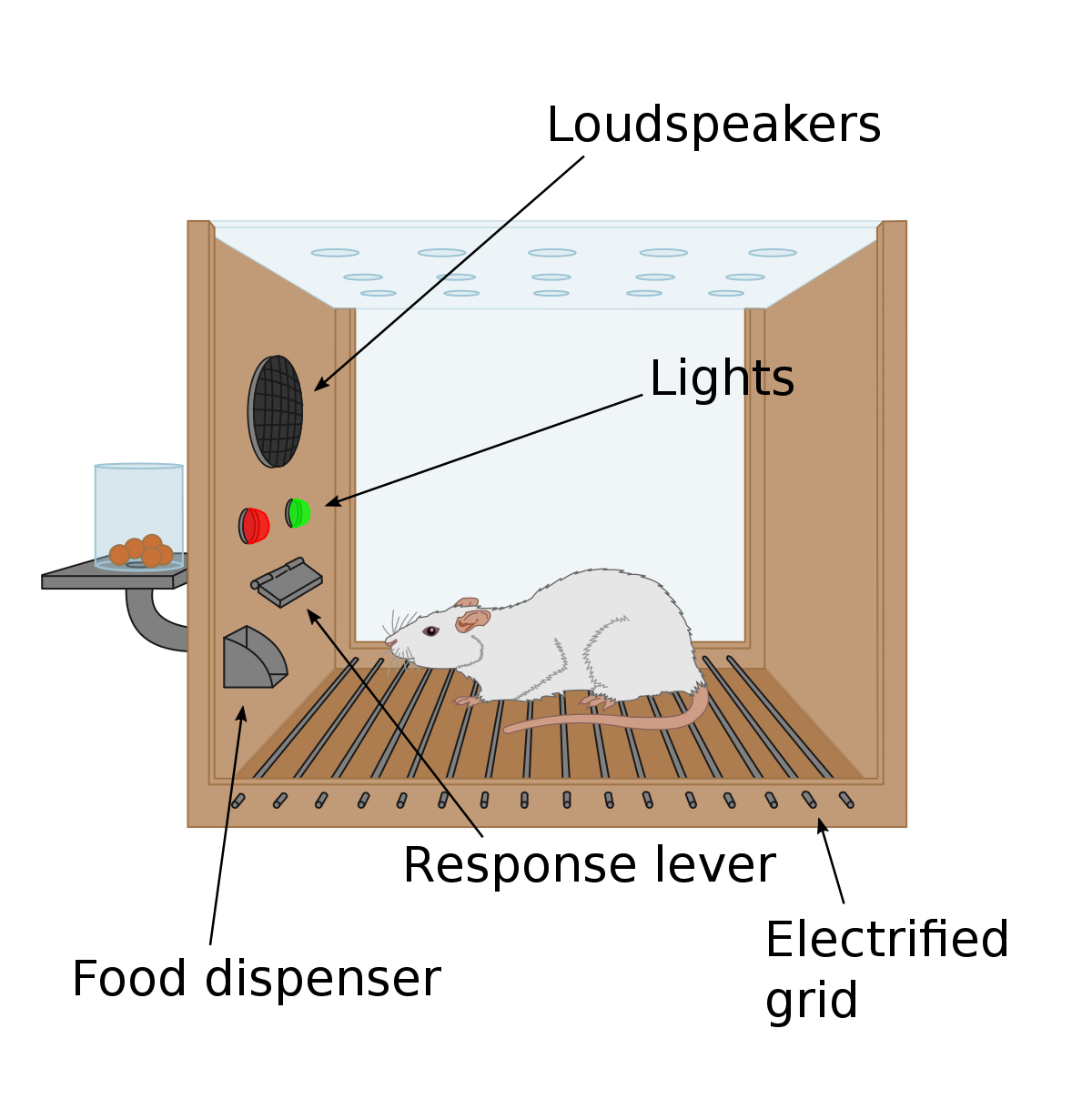

 Jette Nikolajsen
Jette Nikolajsen
 Jesse Spevack
Jesse Spevack





