Domænekendskab i databasemodellering med ChatGPT i informatik

•
3 min læsetid

Et af de vigtigste aspekter af gymnasiefaget informatik er at få eleverne til at forstå og skabe digitale artefakter. Skabelsesprocessen af digitale artefakter indeholder tit en modelleringsproces – en proces, hvor en virkelighed (ofte kaldet for et domæne) skal analyseres og abstraheres og derefter ”oversættes” til en digital (eller computationel) model, der kan realiseres, som enten et digitalt design eller et konkret digitalt artefakt. Denne modelleringsproces illustreres af Caspersen et al. i IT-vests udgivelse Computational Thinking – Hvorfor, hvad og hvordan? fra 2018 med følgende figur:
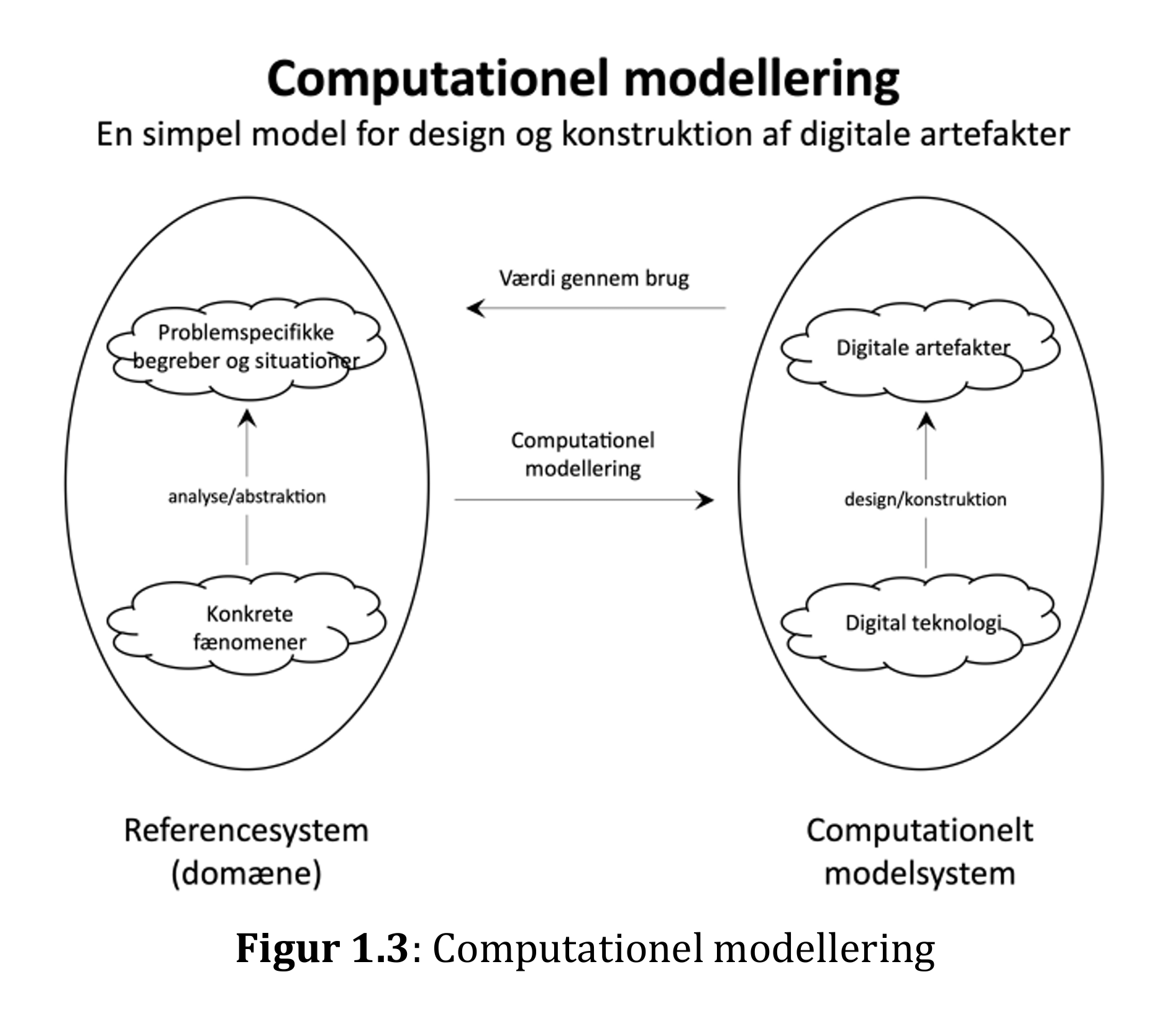
Et af de digitale artefakter, som eleverne skal kunne skabe i informatik, er databaser. Databaser er altid databaser om noget. En modelleringsproces i forbindelse med en database kræver derfor et vist domænekendskab om dette noget. Domænekendskab kan eleverne få ad mange veje. Det kan være gennem allerede eksisterende mindre beskrivelser af et domæne eller forskellige former for desk research. Er der eksempelvis tale om en database til en organisation eller en virksomhed, er det oplagt at benytte deres hjemmeside, hvis de har sådan en.
Man kan argumentere for, at et ordentligt domænekendskab kræver, at eleverne selv bevæger sig ud i verden og laver deres egne observationer og interviews. Dette kan dog være ret tidskrævende, både i forhold til at skabe kontakten og i forhold til at planlægge og foretage observationerne og interviewene.
Et alternativ er at benytte ChatGPT. ChatGPT er overraskende god til at ”rollespille”, og det kan man eksempelvis udnytte til at få et fiktivt domænekendskab til en fiktiv virksomhed. I nedenstående eksempel ”interviewes” ChatGPT som en fiktiv ejer af en cykelbutik:
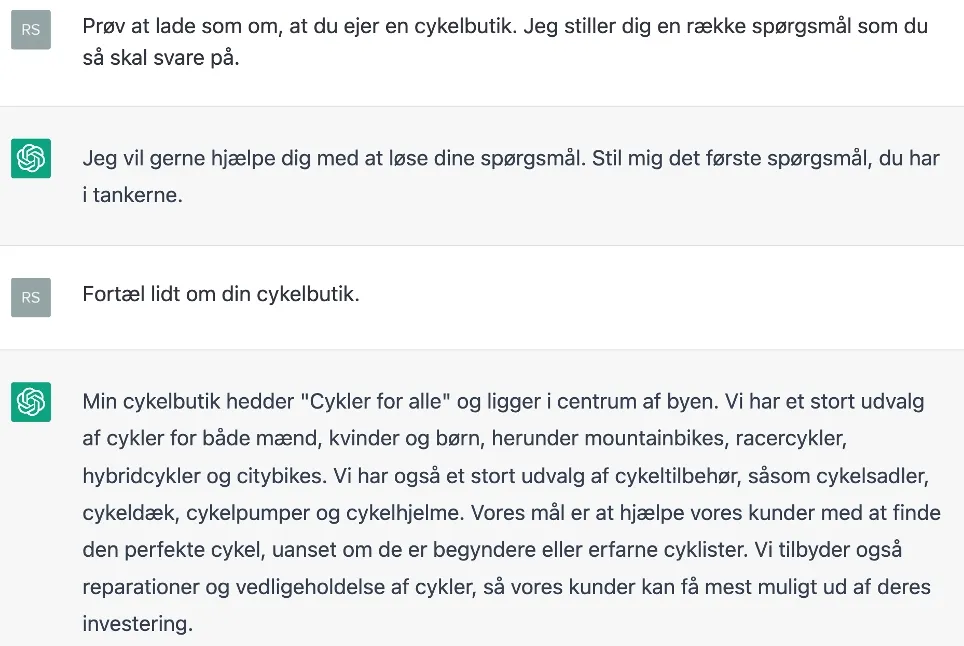
Allerede her har vi fået en række informationer om domænet:
En modelleringsproces af en database handler blandt andet om at oversætte et domænekendskab til en række såkaldte entiteter (kategorier af fænomener) og deres tilhørende attributter (egenskaber ved kategorierne). Ud fra det lille domænekendskab kan vi allerede så småt skitsere, hvilke entiteter og attributter vi kunne have med i vores databasemodel:

For at blive klogere på attributterne, kan vi eksempelvis nu spørge nærmere ind til, hvilken information cykelbutikken har om de forskellige cykler, de sælger:

ChatGPT har således givet os en række yderligere, mulige attributter til entiteten ”Cykler”, og vores opdaterede skitse med disse attributter kunne derfor se således ud:

Vi kunne nemt forsætte vores ”interview”, for på den måde at få sat nogle attributter på entiteterne ”Tilbehør og Reparationer/Vedligeholdelse”. I stedet vil jeg dog her vise, at vi også kan få ChatGPT til at lave et eksempel på, hvordan en egentlig tabel med indhold, baseret på entiteten ”Cykler”, kunne se ud:

Således har vi nu en tabel med mulige data, der er en repræsentation af de cykler, som den fiktive cykelbutik Cykler for alle sælger. Det samme vil kunne gøres med tabeller for entiteterne ”Tilbehør og Reparationer/Vedligeholdelse”.
Dermed vil eleverne nu have det første udkast til både et egentlig E/R-diagram og til tabelstrukturen. Eleverne vil derfor også kunne gå i gang med en normaliseringsproces og i den forbindelse bestemme relationerne mellem de forskellige tabeller.
Således håber jeg at have givet et eksempel på, hvordan ChatGPT, i arbejdet med at skabe et domænekendskab i forbindelse med databasemodellering, kan give nogle muligheder for eleverne, der ikke har været tilstede før.







