
One of the most important aspects of the high school informatics subject is getting students to understand and create digital artifacts. The process of creating digital artifacts often includes a modeling process – a process in which reality (often called a domain) must be analyzed and abstracted and then "translated" into a digital (or computational) model that can be realized as either a digital design or a concrete digital artifact. This modeling process is illustrated by Caspersen et al. in IT-vest's publication Computational Thinking – Why, what and how? from 2018 with the following figure:
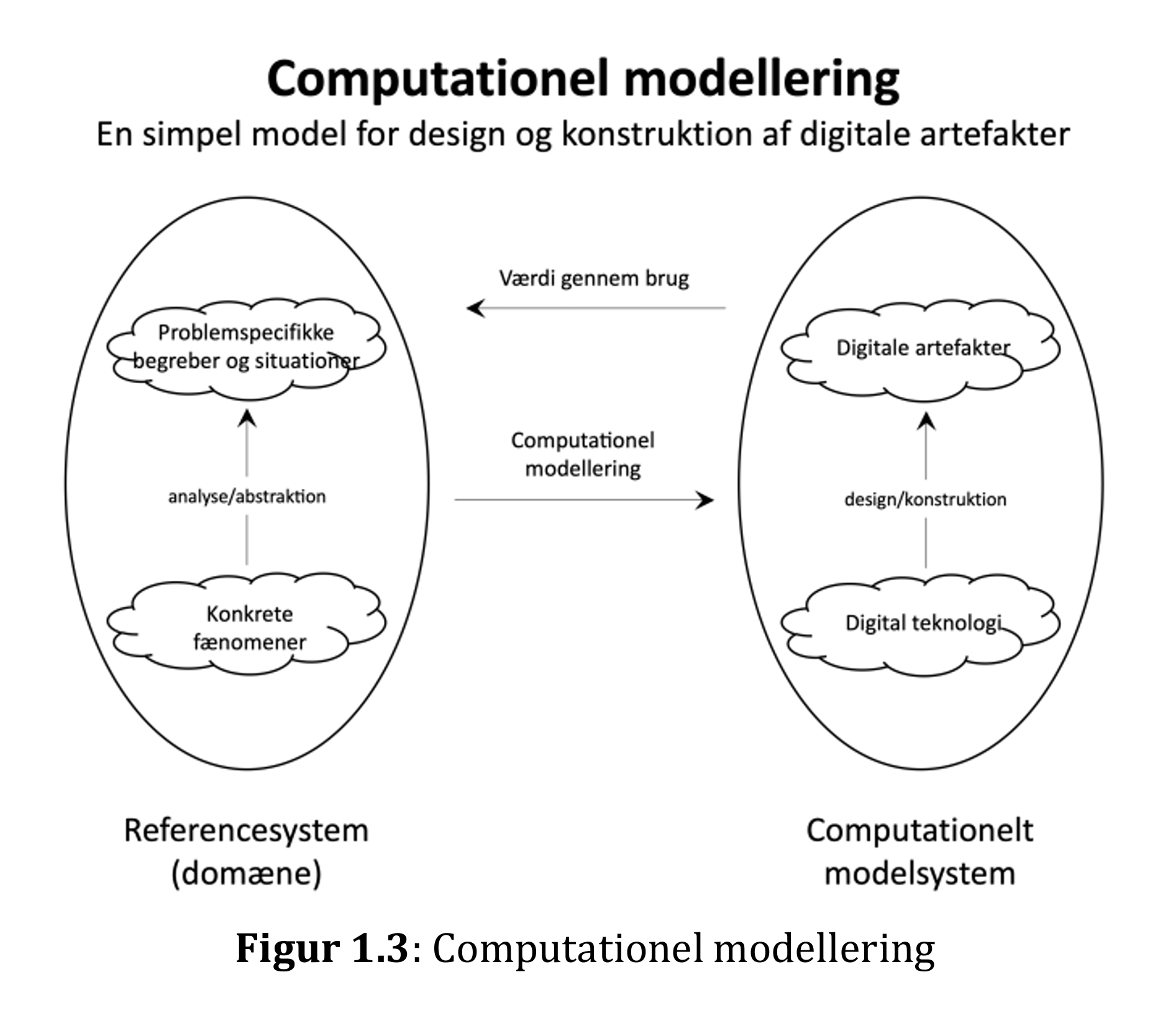
One of the digital artifacts that students should be able to create in informatics is databases. Databases are always databases about something. Therefore, a modeling process in connection with a database requires some domain knowledge of this somewhat. Domain knowledge can be gained by students in many ways. It can be through pre-existing smaller domain descriptions or various forms of desk research. For example, in the case of a database for an organization or a company, it is obvious to use their website if they have one.
It could be argued that proper domain knowledge requires students to go out into the world and conduct observations and interviews. However, this can be quite time-consuming, both in making the contact and planning and making the observations and interviews.
An alternative is to use ChatGPT. ChatGPT is surprisingly good at "role-playing", and you can use this to get a fictitious domain knowledge of a fictitious company. In the example below, ChatGPT is "interviewed" as a fictional bike shop owner:
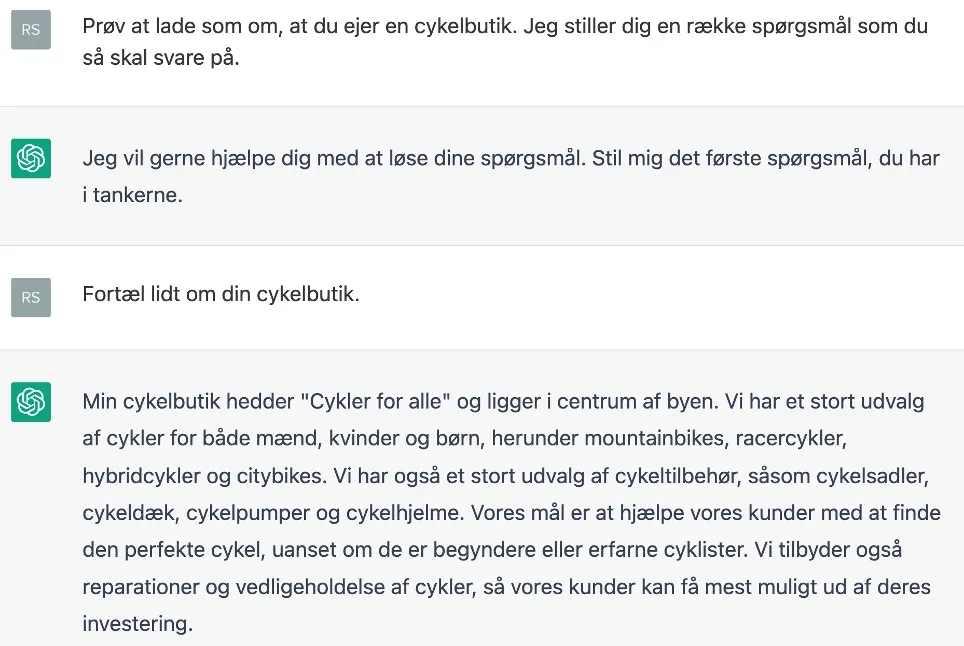
Already here, we have received several pieces of information about the domain:
- The bike shop sells different types of bikes: mountain bikes, racing bikes, hybrid bikes, and city bikes.
- In addition, the store sells various types of accessories, such as bicycle saddles, bicycle tires, bicycle pumps, and bicycle helmets.
- Finally, the bicycle shop carries out various types of bicycle repairs and maintenance tasks.
A modeling process of a database is, among other things, about translating a domain knowledge of several so-called entities (categories of phenomena) and their associated attributes (properties of the categories). Based on the small domain knowledge, we can already sketch out which entities and attributes we could include in our database model:

To learn more about the attributes, we can now ask more about what information the bike shop has about the different bikes they sell:

ChatGPT has thus provided us with several additional possible attributes for the "Bikes" entity, and our updated outline with these attributes could therefore look like this:

We could easily continue our "interview" to add attributes to the "Accessories and Repairs/Maintenance" entities. Instead, I'll show here that we can also have ChatGPT create an example of what an actual table of contents, based on the "Bikes" entity, could look like:

Thus, we have a table with possible data representing the bicycles the fictional bicycle shop Bikes for Everyone sells. The same could be done with tables for the entities "Accessories and Repairs/Maintenance".
Thus, students will have the first draft of an actual E/R diagram and the table structure. The pupils will, therefore, also be able to embark on a normalization process and, in this connection, determine the relationships between the different tables.
Thus, I hope to have provided an example of how ChatGPT, in creating domain knowledge in connection with database modeling, can provide some opportunities for students who have not been present.





